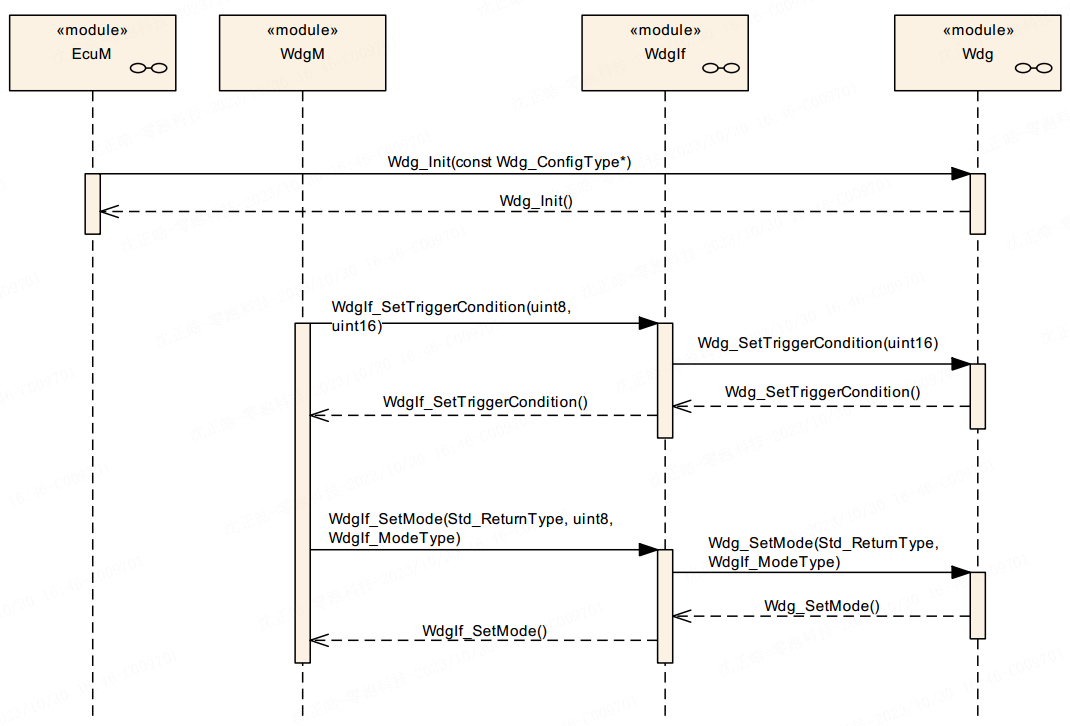
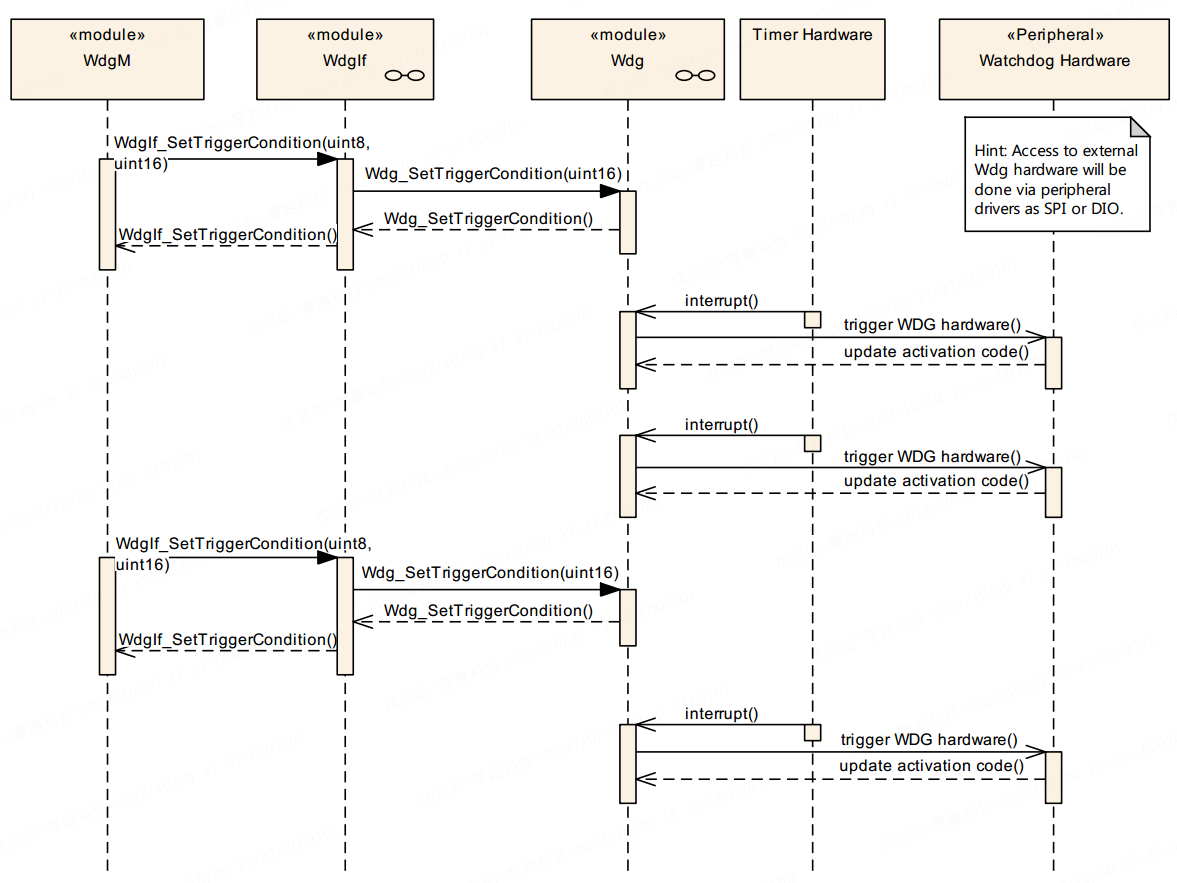
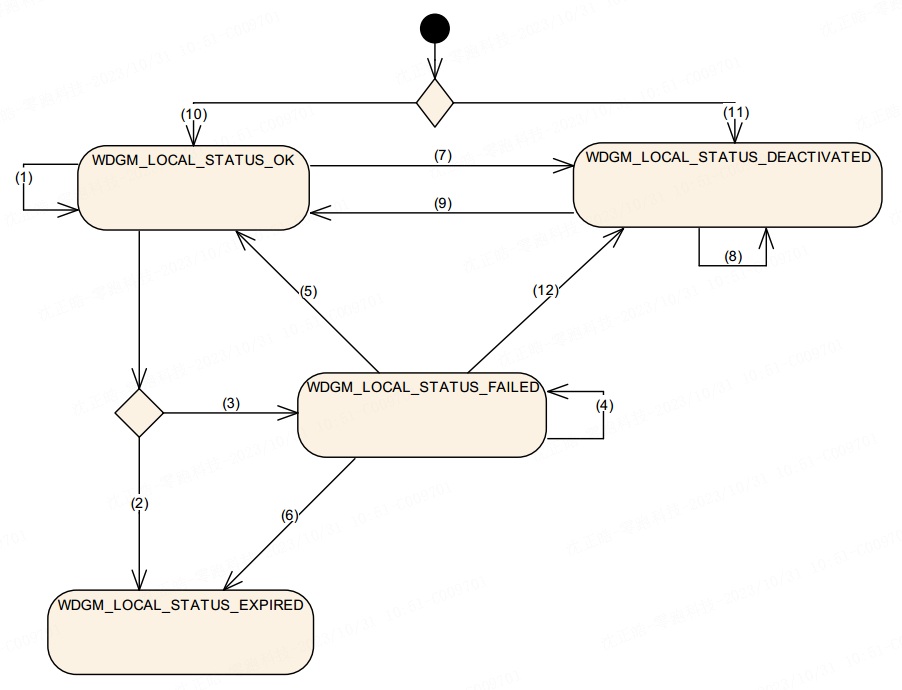
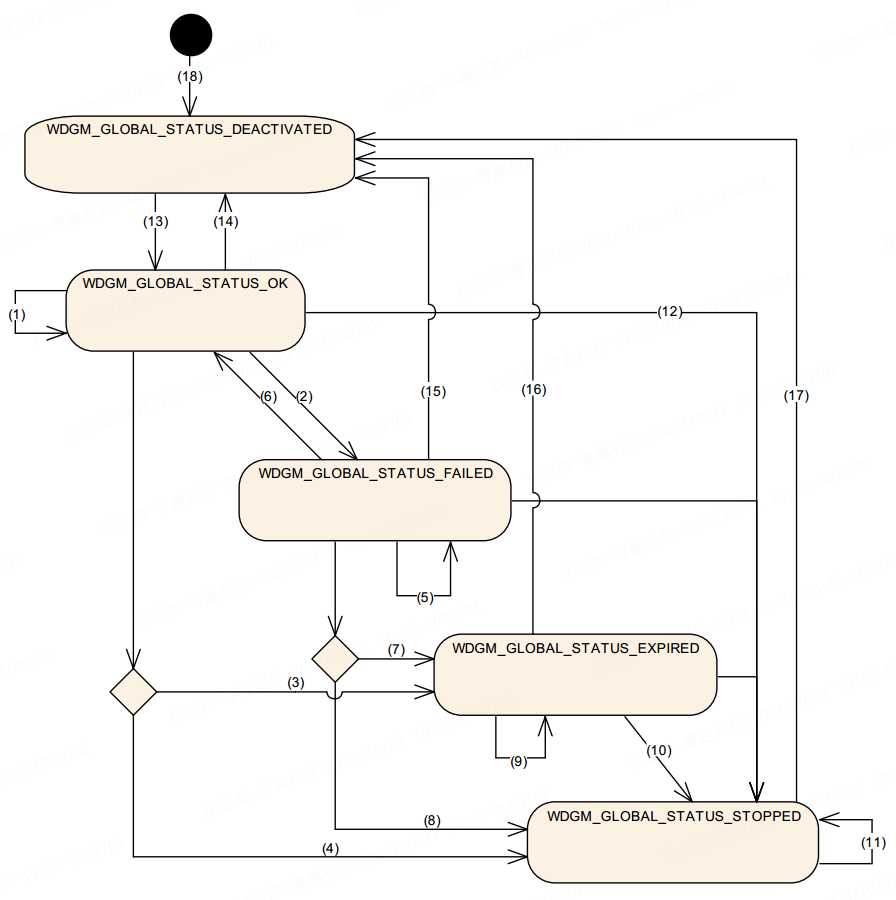
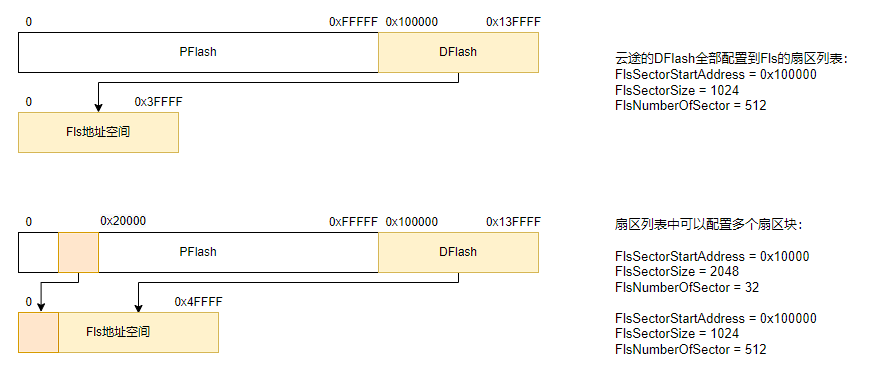
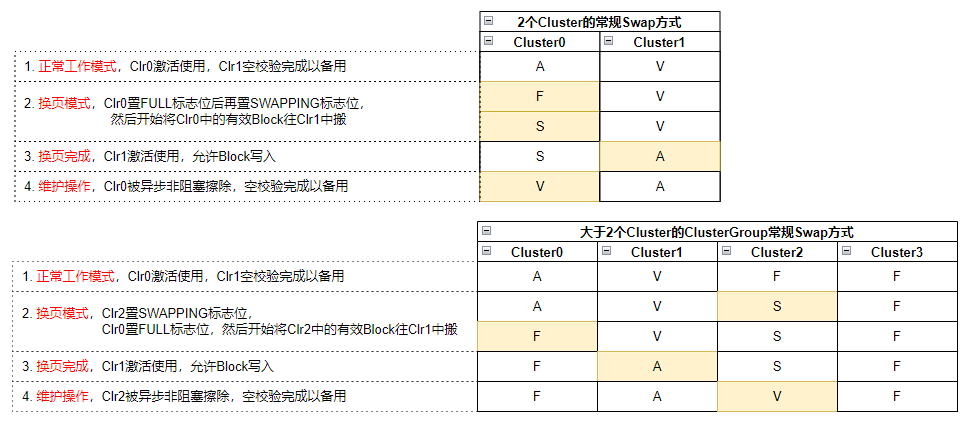
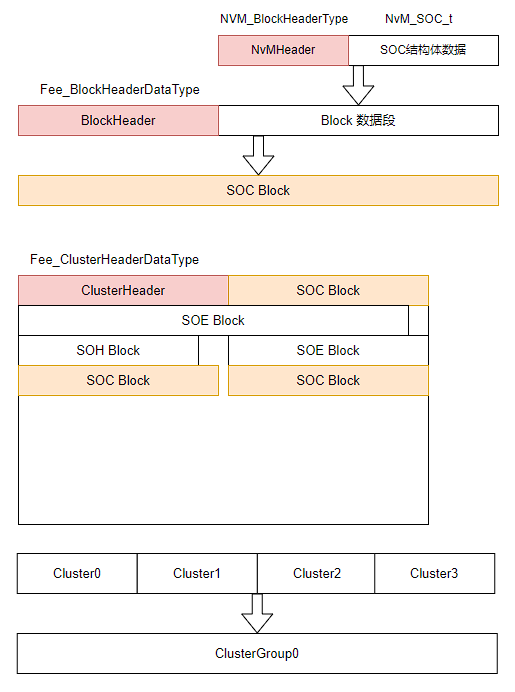
本文主要介绍实际开发中与 CAN FD 波特率参数相关的配置要点。在使用标准 CAN 时,由于通信速率较低,只需确保采样点配置合理,通常不会遇到明显问题。然而在切换至 CAN FD 后,尽管在使用单独的 CAN 卡进行通信测试时一切正常,但在整车网络测试或 HIL 台架(包含多个 CAN 节点)环境下却频繁出现错误帧。在错误帧较多的情况下,可能导致总线通信完全中断,无法发送任何报文。
CAN 波特率基础知识
CAN 位时间的 4 个段
根据 CAN 协议规范,每一个 CAN 位时间(bit time)都被划分为 4 个连续且不重叠的时间段,每个段由若干个时间量化单位(Tq,Time Quantum)构成:
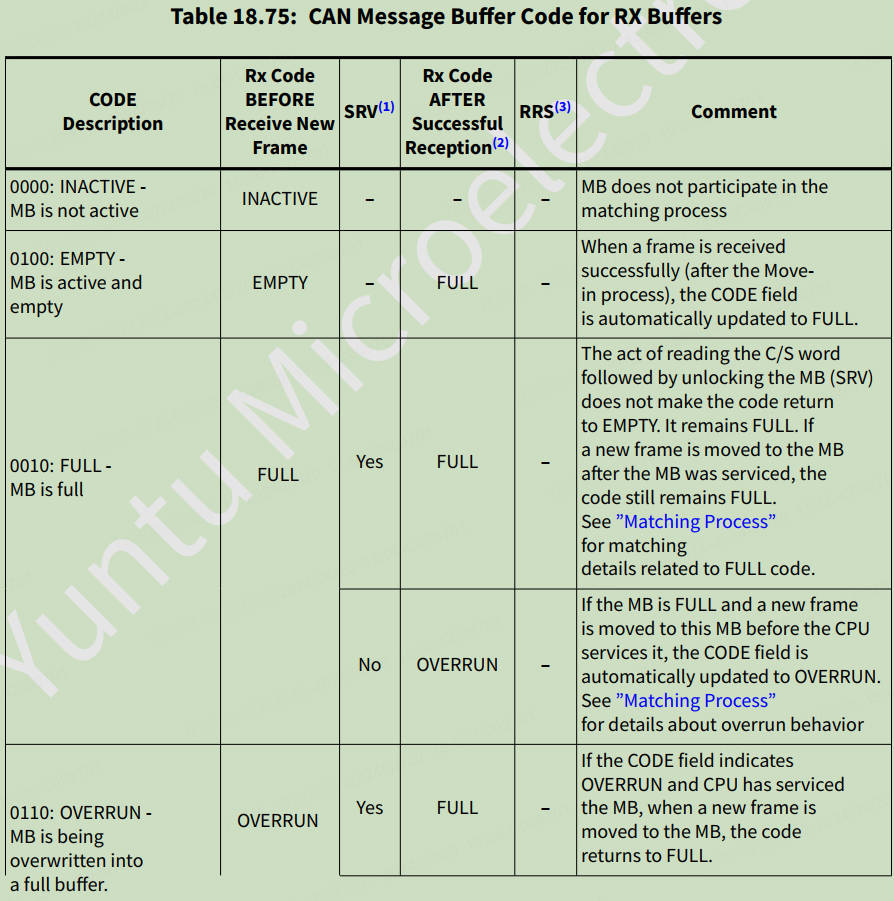
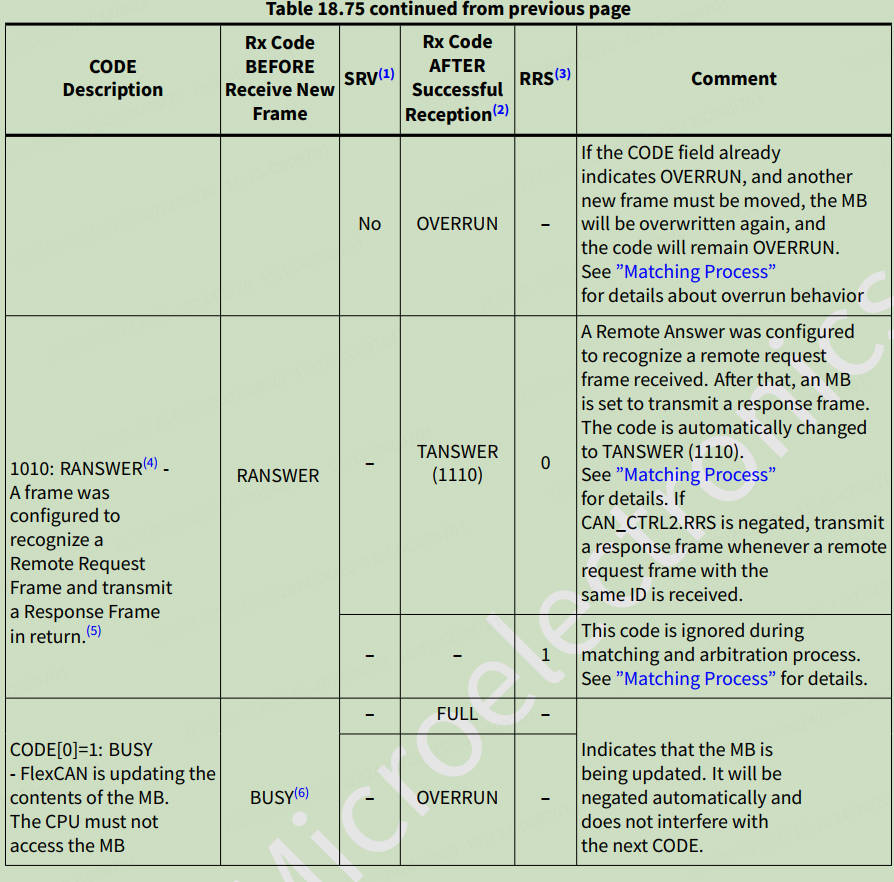
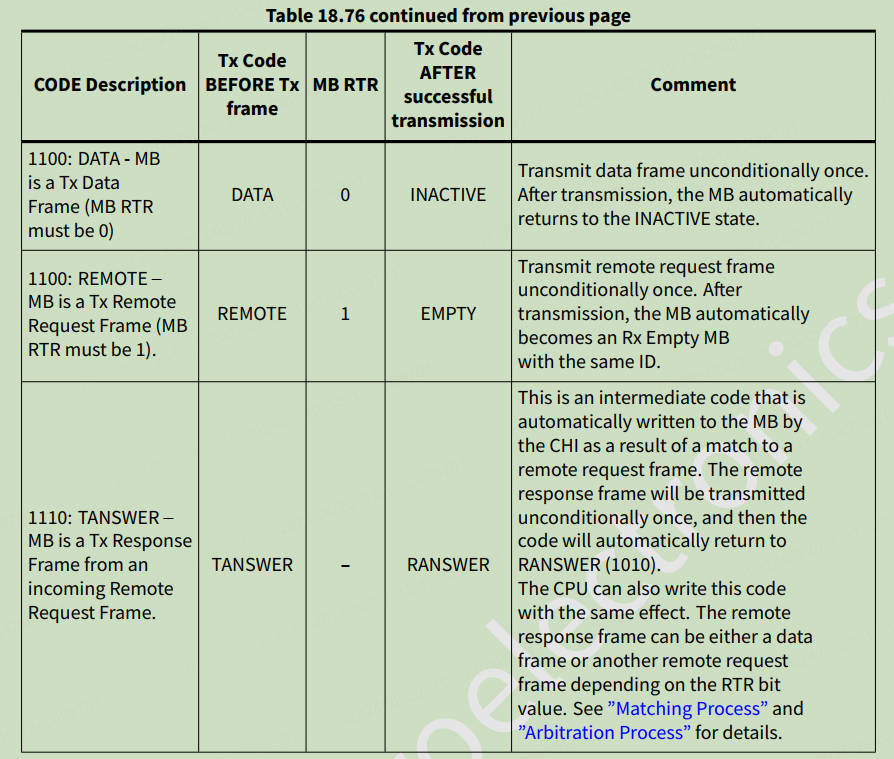
CanFdMb = (CANFD_MB_TYPE *)p_mcuCanTable[channel].p_can->RAMn; CanFdMb[0].mb.t_cs.cs_mb.code = 0x4; //RX EMPTY — MB is active and empty //剩下全部mb用于发送 for (i = 1; i < MailBox; i++){ CanFdMb[i].mb.t_cs.cs_mb.code = 0x8; //TX INACTIVE — MB is not active }
int APIENTRY WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR szCmdLine, int nCmdShow) { /*Initialize LittlevGL*/ lv_init();
/*Initialize the HAL for LittlevGL*/ lv_win32_init(hInstance, SW_SHOWNORMAL, 800, 480, NULL);
/*Output prompt information to the console, you can also use printf() to print directly*/ LV_LOG_USER("LVGL initialization completed!");
/*Run the demo*/ my_decoder_init(); my_show_img();
while(!lv_win32_quit_signal) { /* Periodically call the lv_task handler. * It could be done in a timer interrupt or an OS task too.*/ lv_task_handler(); usleep(10000); /*Just to let the system breath*/ } return0; }
echo Usage: build.bat [--relese ^<LOG_FILE^>] [make target ...] :parse-args rem 检测到没有下个参数,跳到编译 if "%1"=="" ( goto pre-build1 ) if "%1"=="--release" ( rem 解析到--release,还需再读一个后面跟的文件地址 set RELEASE_FLAG=1 set SVN_LOG_FILE=%RUN_PATH%\%2 shift ) else ( rem 其他参数都归自定义make参数 set CUSTOM_MAKE_ARGS=%CUSTOM_MAKE_ARGS% %1 ) rem shift更改参数的位置 shift goto parse-args
::==============================Parse Markdown Function============================ rem 定位Markdown中相应标题所在起始行和结束行 :locateMarkdownTitleFunc echo Entering Function %0 echo inFileName %1 rem titleName需加引号 echo titleName %2
set startLineNum= set endLineNum= rem 查找所有#开头的标题行 for /F "tokens=*" %%iin ('findstr /i /n "^#" %1') do ( set "line=%%i" rem 解析标题行的行号和内容 for /F "tokens=1* delims=:" %%jin ("!line!") do ( set linenum=%%j set "linestr=%%k" rem 已有起始行 没有结束行,设置结束行 if "!startLineNum!" neq "" if "!endLineNum!" equ "" ( set endLineNum=!linenum! ) rem 去标题内容首部#和空格 for /F "tokens=* delims=#" %%ain ("!linestr!") doset "linestr=%%a" for /F "tokens=* delims= " %%ain ("!linestr!") doset "linestr=%%a" rem 标题名匹配 没有起始行,设置起始行(多个匹配使用第一个) if /i "!linestr!" equ %2if "!startLineNum!" equ "" ( set startLineNum=!linenum! ) ) ) rem 有起始行没有结束行则取文件总行数+1作为结束行 if "%startLineNum%" neq "" if "!endLineNum!" equ "" ( for /F %%ain ('find /c /v "" ^< %1') doset /a endLineNum=%%a+1 ) echo Leaving Function %0 goto:eof rem 解析README中的Repo Link表格,设环境变量 :parseRepoLinkFunc echoEnteringFunction %0 echoinFileName %1 echoargsSuffix %2 rem 定位Markdown中Repo Link标题所在起始行和结束行 call:locateMarkdownTitleFunc %1 "Repolink" setRepoLinkStartLineNum=%startLineNum% setRepoLinkEndLineNum=%endLineNum% echoRepoLinkStartLineNum=%RepoLinkStartLineNum% echoRepoLinkEndLineNum=%RepoLinkEndLineNum% rem 解析svn配置行 for /F "tokens=1,2,3,4 delims=^| " %%iin ('findstr /i /n "svn.*http" %1') do ( rem 解析行号 for /F "tokens=1* delims=:" %%ain ("%%i") do ( setlinenum=%%a ) rem 行号大于标题开始行 且 小于标题结束行 则解析,设环境变量 if !linenum! gtr %RepoLinkStartLineNum% if !linenum! lss %RepoLinkEndLineNum% ( setSvnUrlMd_%2=%%l ) ) rem 解析git配置行 for /F "tokens=1,2,3,4 delims=^| " %%iin ('findstr /i /n "git.*http" %1') do ( rem 解析行号 for /F "tokens=1* delims=:" %%ain ("%%i") do ( setlinenum=%%a ) rem 行号大于标题开始行 且 小于标题结束行 则解析,设环境变量 if !linenum! gtr %RepoLinkStartLineNum% if !linenum! lss %RepoLinkEndLineNum% ( setGitUrlMd_%2=%%l setBranchMd_%2=%%k ) ) echoLeavingFunction %0 goto:eof rem 解析README中的Config表格,输出到文件 :parseConfigFunc echoEnteringFunction %0 echoinFileName %1 echooutFileName %2 rem 清空outFile del %2 2>nul rem 定位Markdown中Config标题所在起始行和结束行 call:locateMarkdownTitleFunc %1 "Config" setConfigStartLineNum=%startLineNum% setConfigEndLineNum=%endLineNum% echoConfigStartLineNum=%ConfigStartLineNum% echoConfigEndLineNum=%ConfigEndLineNum% rem 查找Config标题中Config Name所在行 for /F "tokens=*" %%iin ('findstr /i /n /c:"ConfigName" %1') do ( for /F "tokens=1* delims=:" %%ain ("%%i") do ( setlinenum=%%a if !linenum! gtr %ConfigStartLineNum% if !linenum! lss %ConfigEndLineNum% ( rem 设置Config Table内容开始行 set /atableStart=!linenum!+2 ) ) ) rem 逐行遍历Markdown文件 for /F "tokens=1,2,3,4 delims=^| " %%iin ('findstr /i /n "^" %1') do ( rem 解析行号 for /F "tokens=1* delims=:" %%ain ("%%i") do ( setlinenum=%%a ) rem 行号大于等于表格内容开始行则解析 if !linenum! geq %tableStart% ( setconfigName=%%j setconfigValue=%%k rem 检测为空判定为表格结束,退出函数 if "!configName!" equ "" ( gotoleaveParseConfig ) if "!configValue!" equ "" ( gotoleaveParseConfig ) rem 存到输出文件 echo !configName!=!configValue!>>%2 echo !configName!=!configValue! rem 是PostSyncJob 则 设环境变量 if "!configName!" equ "PostSyncJob" ( setPostSyncJob=!configValue! ) ) ) :leaveParseConfig echoLeavingFunction %0 goto:eof ::=================================================================================
// if the name of the executable ends in "encoder" or "decoder", just do that function encode_only = argc && strstr (argv [0], "encoder") && strlen (strstr (argv [0], "encoder")) == strlen ("encoder"); decode_only = argc && strstr (argv [0], "decoder") && strlen (strstr (argv [0], "decoder")) == strlen ("decoder");
// loop through command-line arguments
while (--argc) { #if defined (_WIN32) if ((**++argv == '-' || **argv == '/') && (*argv)[1]) #else if ((**++argv == '-') && (*argv)[1]) #endif while (*++*argv) switch (**argv) {
// if the name of the executable ends in "encoder" or "decoder", just do that function encode_only = argc && strstr (argv [0], "encoder") && strlen (strstr (argv [0], "encoder")) == strlen ("encoder"); decode_only = argc && strstr (argv [0], "decoder") && strlen (strstr (argv [0], "decoder")) == strlen ("decoder");