课程链接
课程笔记
L1~L3
课程目标:进入操作系统,学习操作系统的运作。
计算机工作方式:取址执行,取CS和PC指针指向内存中的指令,在CPU执行
操作系统引导:启动引导时内核在内存中的位置和移动后的位置情况图
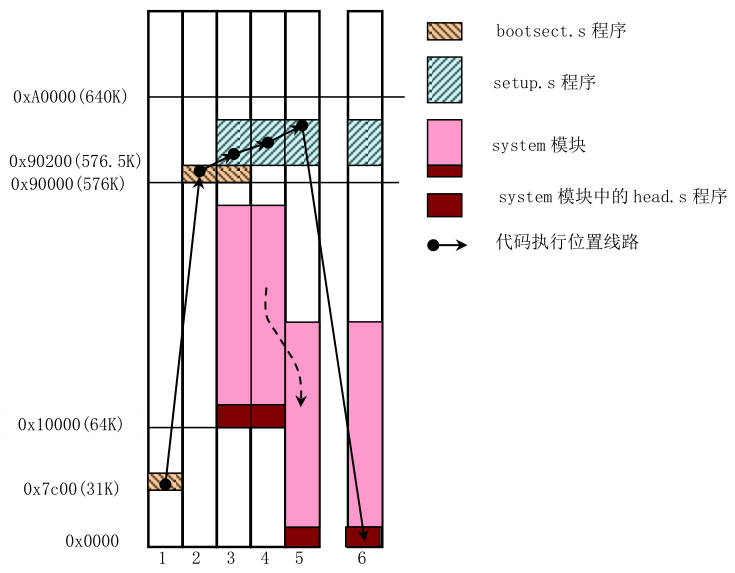
开机时,CS=0xffff,IP=0x0000,CPU处于实模式。实模式寻址CS<<4+IP,CS存放段地址,IP存放4位段偏移量,共20位。0xffff0地址属于BIOS映射区,在BIOS里检查硬件(RAM,键盘,…);
将磁盘0磁道0扇区(引导扇区)读到内存0x7c00,引导扇区代码存放在bootsect.s;
将引导扇区代码从内存0x7c00处移动到0x90000处;
jmpi go, INITSEG,INITSEG=0x9000,跳至bios的go标号处;jmpi 0, SETUPSEG,SETUPSEG=0x9020,跳至setup.s;在setup.s start:中读取扩展内存大小,读取显卡参数,…;
do_move:中将system模块移动到0地址,
jmpi 0, 8,跳转到system模块,system模块开始是head.s;通过设置cr0最后一位,PE=1由16位实模式转到32位保护模式,在保护模式下,CS表示选择子,查GDT表得到;
在head.s中初始化GDT表和IDT表,setup_paging执行ret后,会执行函数main(),进入main()后的栈为0,0,0,L6,三个0表示main函数的参数,L6表示main函数返回时进入死循环;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15after_page_tables:
pushl $0 # These are the parameters to main :-)
pushl $0 # 这些是调用 main 程序的参数(指 init/main.c)。
pushl $0 # 其中的'$'符号表示这是一个立即操作数。
pushl $L6 # return address for main, if it decides to.
pushl $_main # '_main'是编译程序对 main 的内部表示方法。
jmp setup_paging # 跳转至第 198 行。
L6:
jmp L6 # main should never return here, but
# just in case, we know what happens.
# main 程序绝对不应该返回到这里。不过为了以防万一,
# 所以添加了该语句。这样我们就知道发生什么问题了。
setup_paging:
设置页表...
ret
L4~L7
- 操作系统接口:接口表现为函数调用,又由系统提供,所以称为系统调用,可移植操作系统接口(Portable Operating System Interface of uniX, POSIX)
- 系统调用的实现:应用层要通过接口访问内核,不能直接读内核内存,内核是受保护的。中断是进入内核的唯一方法;
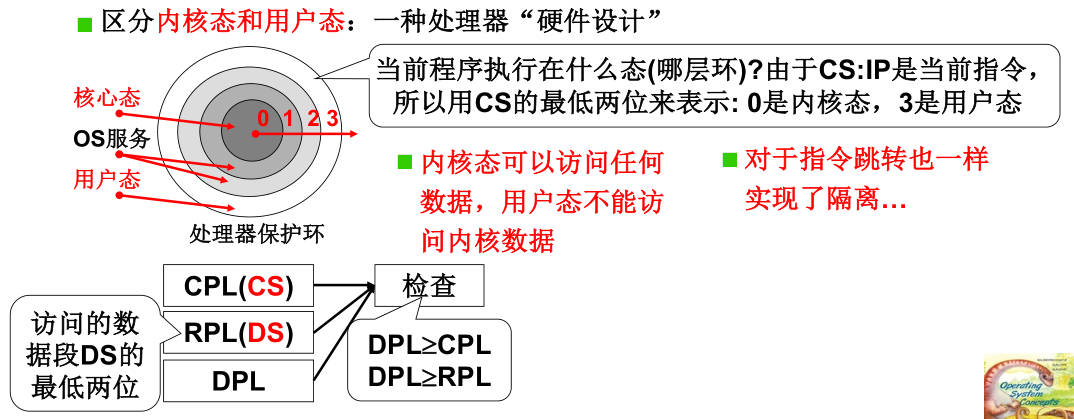
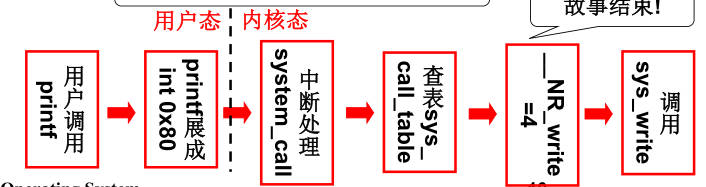
- 课程任务:操作系统要学习CPU管理、内存管理、文件管理;
L8~L19
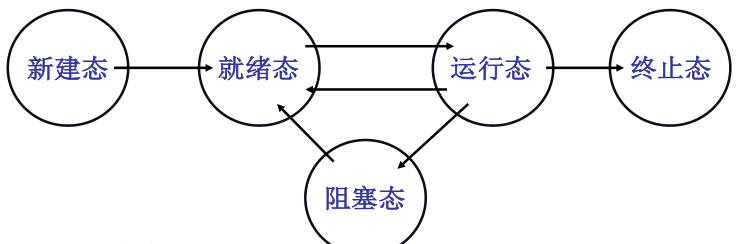
CPU管理:多道程序,交替执行(并发)。运行的程序是进程,多进程切换时要保存现场。通过进程控制块(Process Control Block, PCB)来记录进程信息。操作系统要把这些进程记录好,要按照合理的次序分配资源、调度;
进程状态图:
通过进程内存映射表来实现内存分离,切换进程时要切换内存映射表;通过上锁,来保证共享内存的正确被读写;
用户级线程和核心级线程区别:用户级线程创建、切换无需进内核,一个线程阻塞进程会被切换;
线程的优点:线程切换无需切换内存映射表。
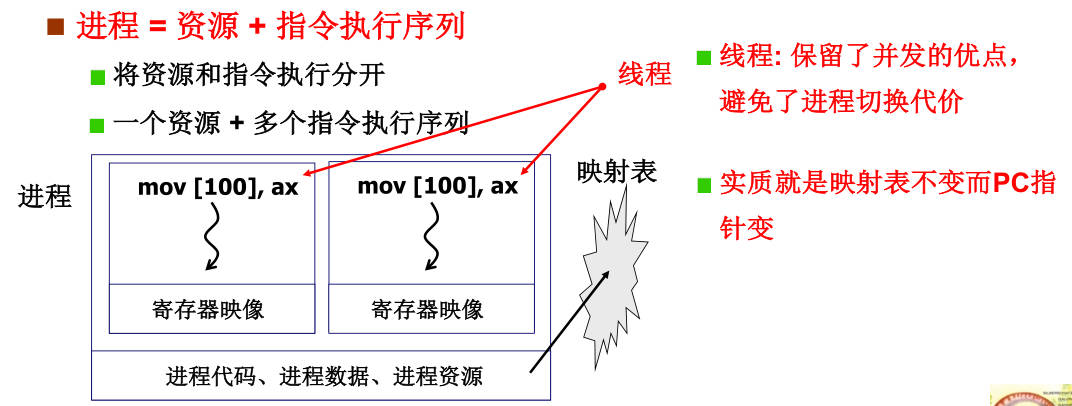
用户级线程切换通过Yield(),要先切换栈,栈会存在TCB(线程控制块)中,每个线程对应一个TCB;
核心级线程切换时除了用户栈还有内核栈也要一起切换。在内核阻塞时要进行TCB切换,使用
switch_to(cur, next);TCB切换完后根据TCB完成内核栈切换,最后IRET返回用户态,切换用户栈;前台任务需要响应时间小->导致切换次数多->导致系统内耗大->导致吞吐量(完成任务的量)小。后台任务更加关注周转时间。任务可分成IO约束型任务和CPU约束型任务;
CPU调度策略:FIFO、Priority;CPU调度算法:先来先服务(First come, first served),短作业优先(SJF)这个算法周转时间最小,按时间片来轮转调度(RR),优先级调度(前台>后台);
linux0.11中的调度函数既考虑了优先级又考虑了时间片:
1
2
3
4
5
6
7
8
9void Schedule(void) // 在 kernel/sched.c 中
{ while(1){ c=-1; next=0; i=NR_TASKS; p=&task[NR_TASKS];
while(--i){ if((*p->state == TASK_RUNNING&&(*p)->counter>c)
c=(*p)->counter, next=i; }
if(c) break; // 找到了最大的counter,跳出,执行switch_to()
for(p=&LAST_TASK;p>&FIRST_TASK;--p)
(*p)->counter=((*p)->counter>>1)+(*p)->priority;
}
switch_to(next);}进程间同步看信号量(Semaphore),可使多个进程合理有序运行。读写信号量的代码一定在临界区,或者原子操作。临界区:一次只允许一个进程进入该进程的那段代码。原子操作:不会被线程调度机制打断的操作;
保护临界区的方法:关闭中断
cli();,临界区,开中断sti();,剩余区。这种方法只适用于小系统,不适用于多核CPU。还可以采取硬件原子指令法,硬件一条指令修改mutex变量;信号量未互斥使用会造成死锁。死锁处理:死锁预防,死锁避免,死锁检测+恢复,死锁忽略;
L20~L25
- 内存使用:将程序放到内存中,PC指向开始的地址。将程序从硬盘载入内存需要重定位,物理地址=基址+逻辑地址。重定位可以在编译时(静态系统)、载入时执行、运行时执行。编译时重定位的程序只能放在内存固定位,载入时重定位的程序一旦载入内存就不能动了;
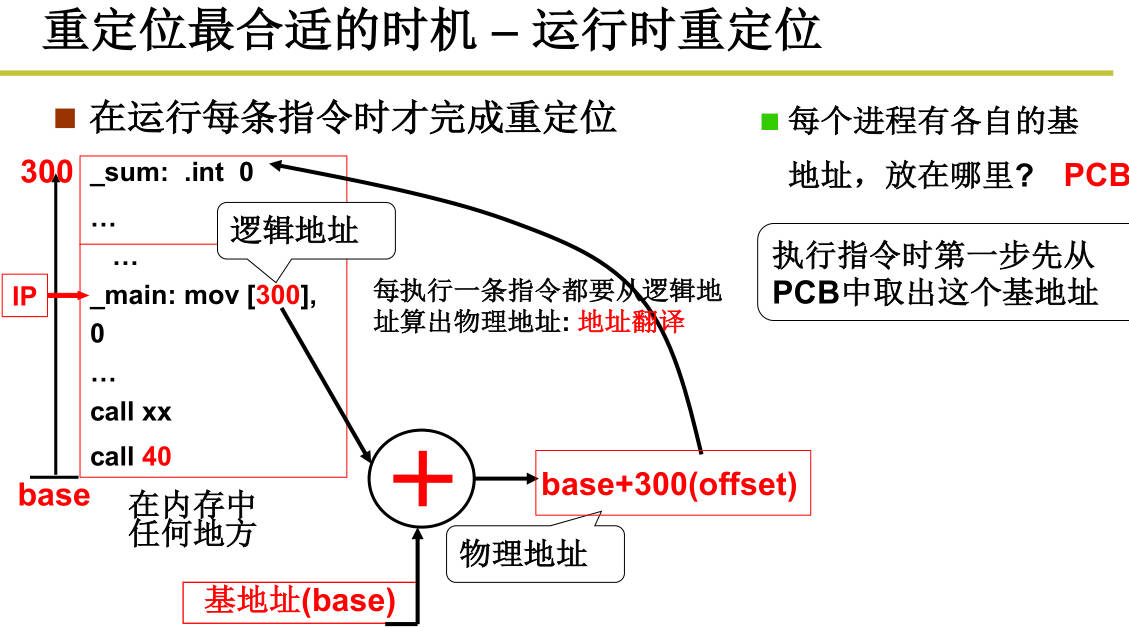
程序载入后还需要移动,引入交换(swap)概念,可以把暂时不用的内存搬到交换分区,充分利用内存。
引入分段,程序由若干部分(段)组成,每个段有各自的特点、用途:主程序(只读)、变量集(可写、不会动态增长)、函数集、动态数组(会动态增长)、栈。使用分段思想可以让用户分治每个段,可以让内存更高效使用。定位具体指令
mov [es:bx], ax。地址组成:<段号,段内偏移>。进程段表存放在LDT表,系统段表存放在GDT表,LDT存放在PCB中;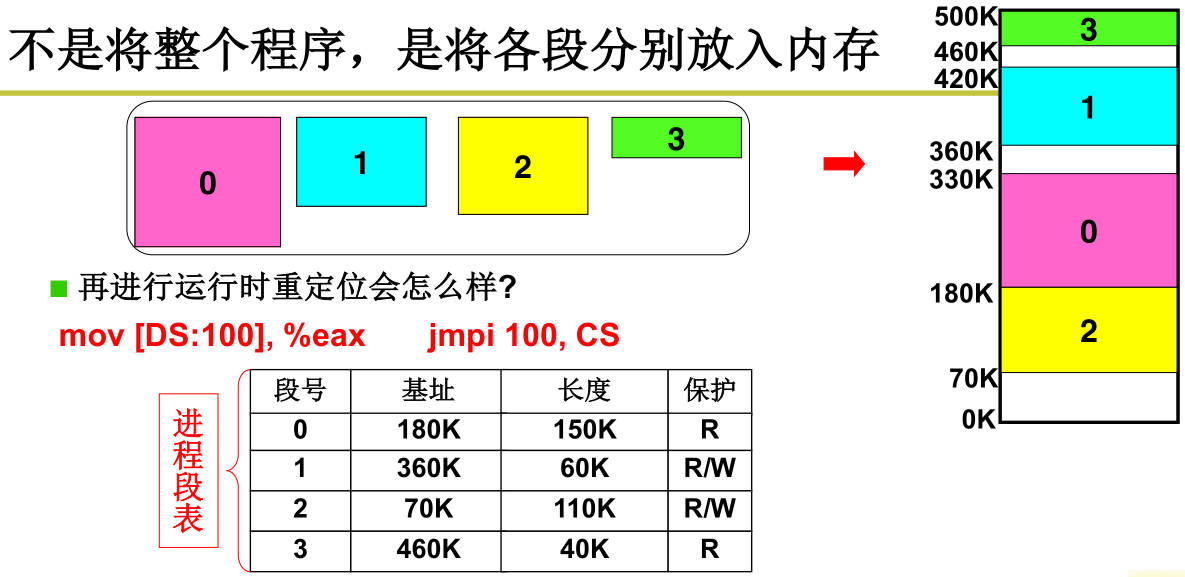
内存分区可分为固定分区和可变分区。可变分区的管理:空闲分区表、已分配分区表。可变分区分配内存算法:首先适配(最快)、最佳适配和申请空间长度最接近(会导致内存碎片)、最差适配;
实际物理内存采用分页来管理,分区是对虚拟内存(交换分区)的管理方法。分区会造成内存碎片,分页会将物理内存分割(比如每4k分割),程序也会被分页,每段都会被分页,分页会使内存存储离散化。地址翻译有专门的硬件内存管理单元(MMU)执行;
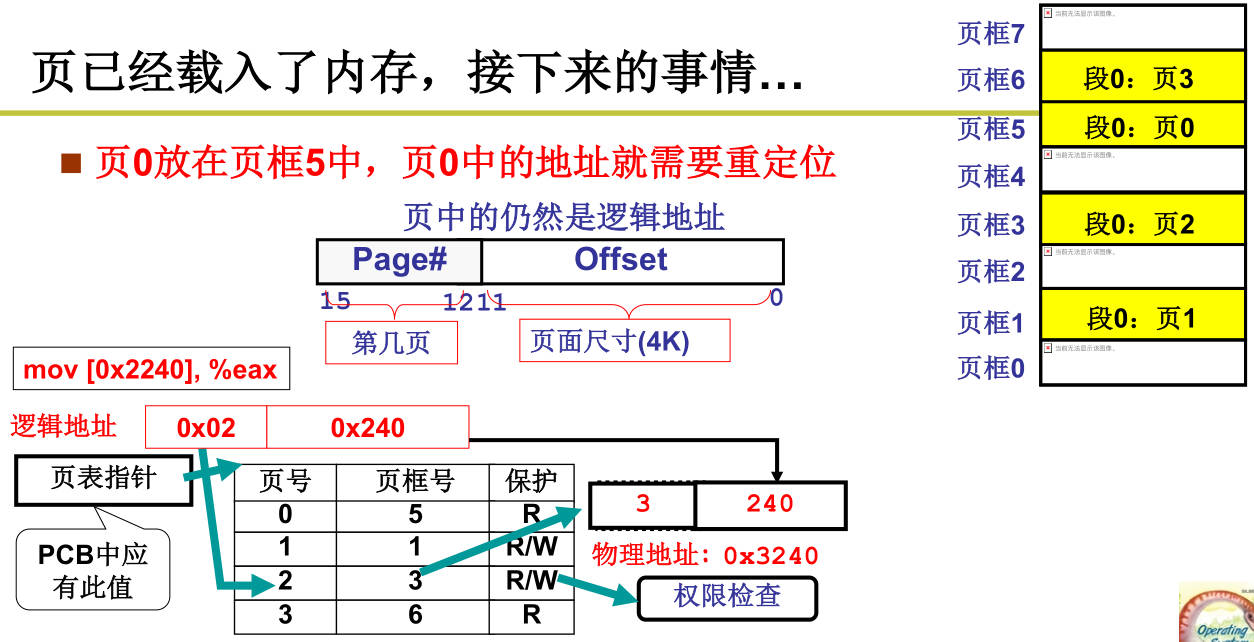
为了提高内存空间利用率,页应该小,但是页小了页表就大了。如果页表只存放用到的页,则需要顺序查找页表,速度慢。采用多级页表可兼顾速度和空间,即页目录表+页表,地址组成<10bits页目录号,10bits页号,12bits偏移>,12bits偏移刚好是4K。
多级页表增加了访存的次数,尤其是64位系统。硬件上引入转译后备缓冲区(Translation Look-aside Buffer,TLB,快表),快表能存放最近查过多级页表的逻辑页和物理页,可以根据页号直接查物理页号;

段页结合:段面向用户,页面向硬件。实际的段页内存管理,程序如何载入内存,fork后内存做了什么可以看L23 段页结合的实际内存管理;
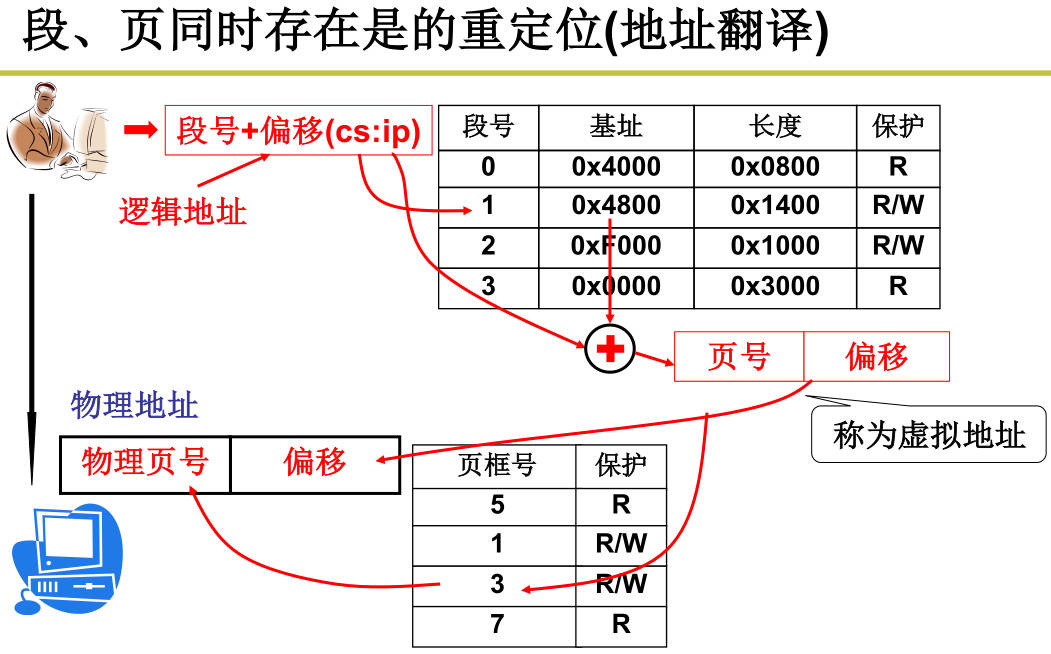
用内存换入换出实现“大内存”,虚拟内存4G,物理内存可以只有1G。当程序运行缺页时, page fault中断请求do_no_page调页(读磁盘),这就是换入;
- 内存换出:将内存中不用的页换出到磁盘。如何找不用的页?换出算法:FIFO(先来的先被换出,不太行)、MIN(将未来最远要使用的页淘汰,是最优方案,但无法预测未来)、LRU(Least Recently Used,最近最少使用);
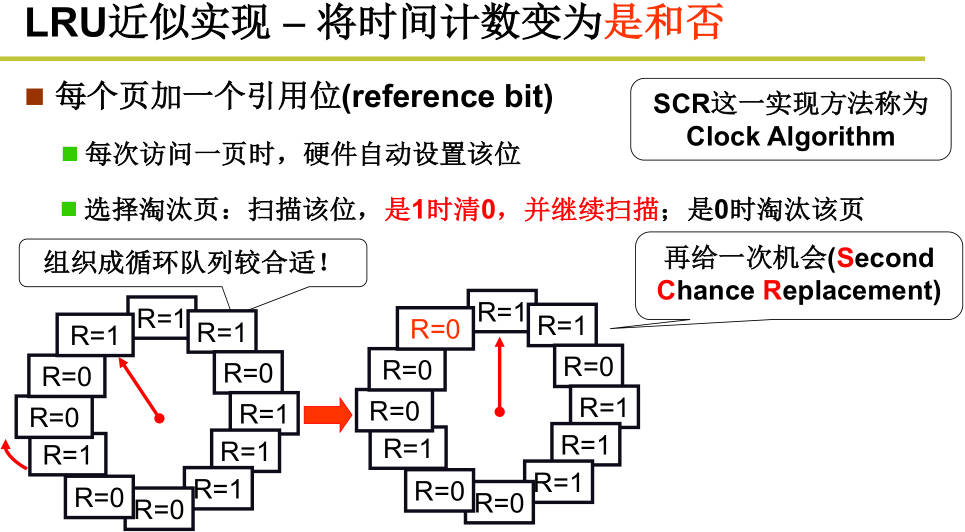
- LUR的准确实现:可以用时间戳,每次地址访问都需要修改时间戳,需维护一个全局时钟,实现代价较较大,可以用页码栈,选择栈底淘汰,代价也太大。在实际中内存换出算法采用LUR的近似实现:时钟算法(环形队列)
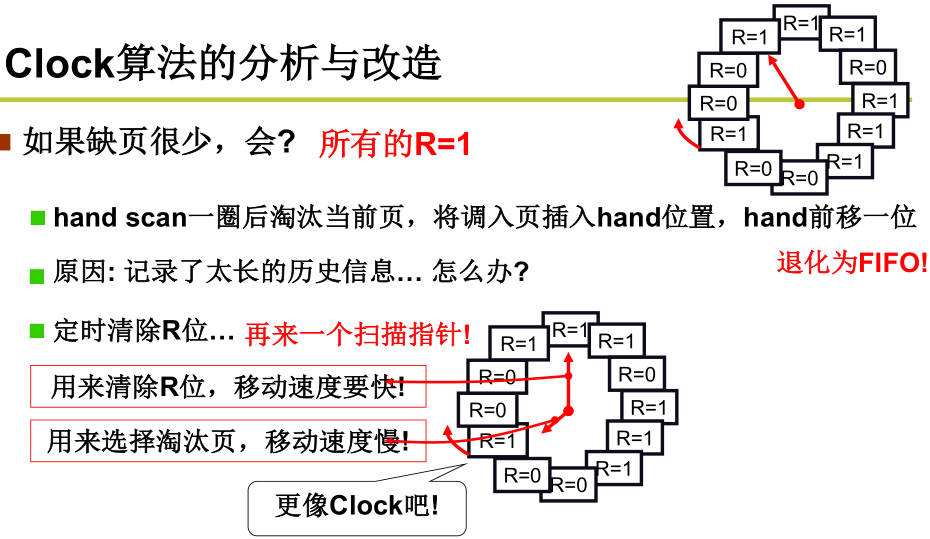
- 给进程分配多少页框?分配多了,请求调页导致的内存高效利用就没有了。分配少了,会频繁请求调页导致系统低效。系统低效解释:系统内进程增多多,每个进程的缺页率增大大,缺页率增大到一定程度,进程总等待调页完成,CPU利用率降低低,进程进一步增多,缺页率更大,称这一现象为颠簸(thrashing);
L26~L32
- IO设备、显示器、键盘,让这些外设工作的基本思想就是往外设硬件寄存器写值,外设处理完再产生中断,CPU处理。在Linux中无论什么设备都用文件接口open、read、write、close,例如
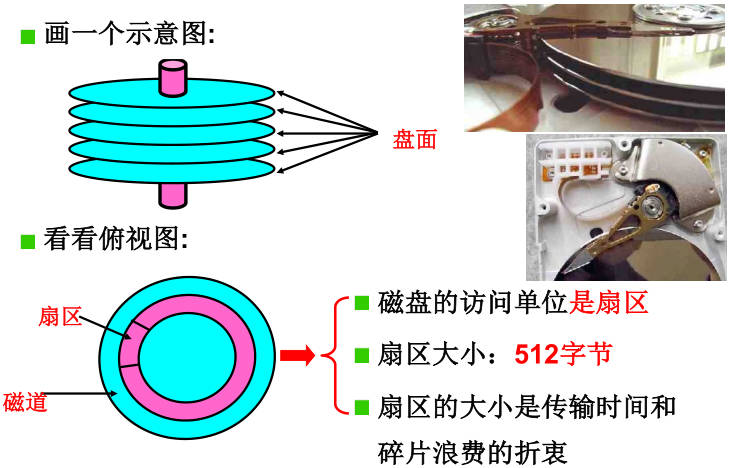
int fd = open("/dev/xxx");到最后是通过out写对应寄存器; - 生磁盘的使用:磁盘驱动负责从盘块号(block)计算出柱面(cgl)、磁头(head)、扇区号(sec)。从CHS到扇区号,从扇区到盘块(第一层抽象):扇区号 = C×H×S+H×S+S 。
- 多个进程通过请求队列使用磁盘(第二层抽象);
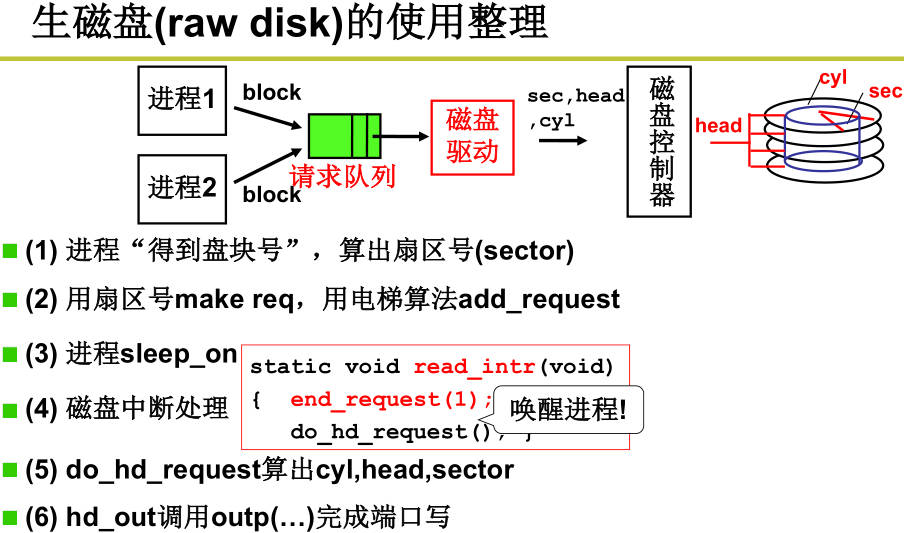
访问磁盘时间 = 写入控制器时间 + 寻道时间(8~12ms)+ 旋转时间(7200rmp,半周4ms)+ 传输时间(50MB/s,约0.3ms)。可见访问磁盘主要时间花在寻道,block相邻的盘块可以快速读出,因此需要考虑寻道算法。寻道调度算法有FCFS(先来先服务)、SSTF(短寻道优先算法,可能有磁道长时间访问不到)、SCAN(SSTF+中途不折回)、C-SCAN(SCAN+直接移动到另一端,电梯算法);
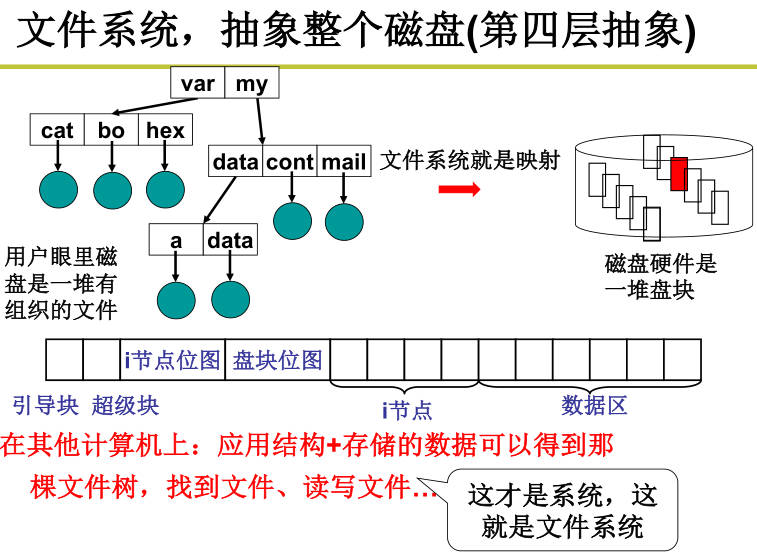
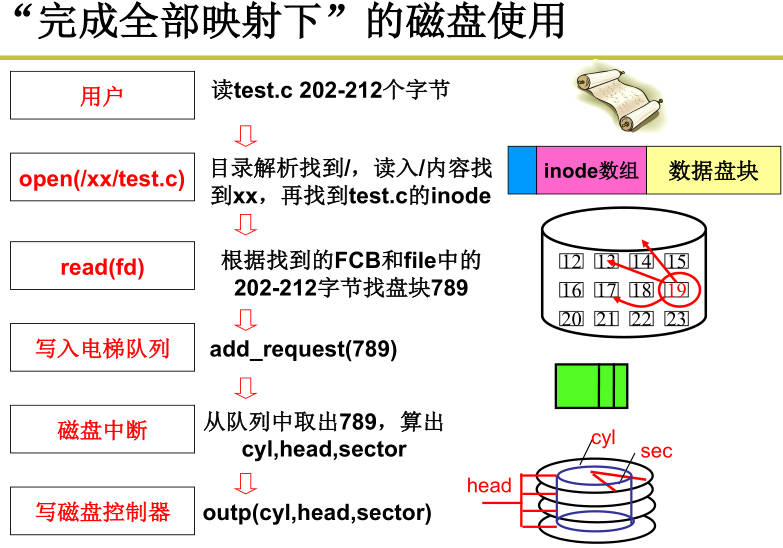
引入文件(第三层抽象),文件是建立字符流在磁盘块集合的映射关系,每个文件都对应一个文件控制块(FCB),连续结构存储FCB包含文件名、起始块、块数的信息,链式结构存储FCB包含文件名、起始块的信息,链式结构存储顺序访问慢、可靠性差,索引结构存储文件是连续和链式的有效折中,FCB包含文件名、索引块的信息。在实际系统中采用的是多级索引结构,根据不同大小文件分成不同级索引通过inode一级级查询访问,因此可以标识很大的文件,很小的文件可以高效访问,中等大小的文件访问速度也不慢;
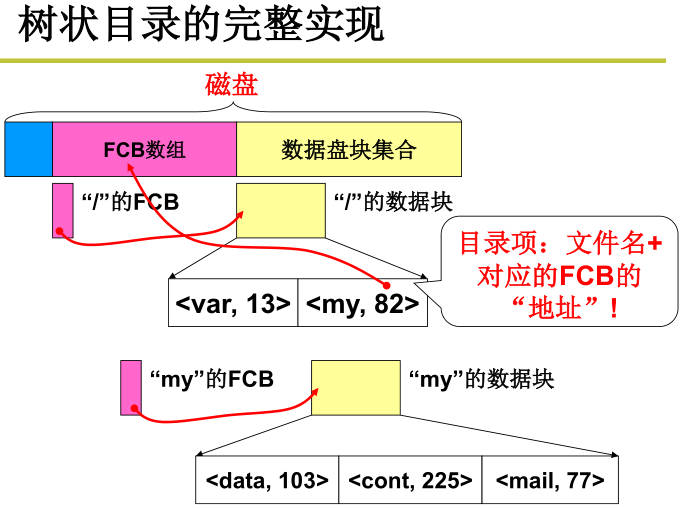
引入文件系统(第四层抽象),文件系统引入目录树,文件目录也是个文件,存放目录下其他文件名和对应文件的FCB指针。inode位图:哪些inode空闲,哪些被占用。盘块位图:哪些盘块是空闲的,硬盘大小不同这个位图的大小也不同。超级块:存放i节点位图和盘块位图的大小,因此可以计算出i节点起始地址;
课程总结
通过本次操作系统的学习,了解了操作系统全图(CPU、内存、文件设备),学习了多进程视图、文件视图。哈工大的几个实验非常的难,Study OS by coding !!!