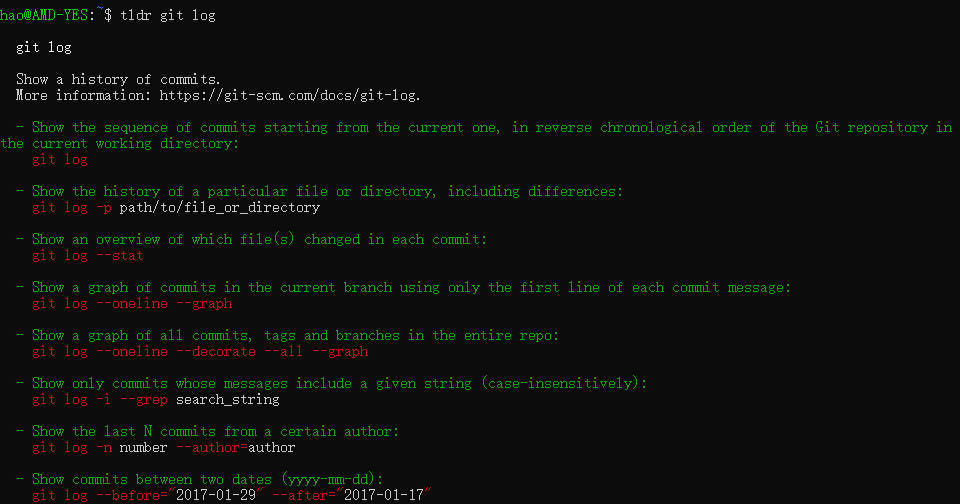
起因
这几天在做云途单片机的flash接口移植,同时陀螺仪的代码也需要将校准参数保存到flash每次开机读取,于是就看了s32k单片机的flash操作和模拟eeprom,同时看了云途的手册和sdk,也看了stm32闪存编程参考手册和hal库。
参考资料
- 【正点原子】 手把手教你学STM32入门教学视频单片机 嵌入式 之 F103-基于新战舰V3/精英/MINI板
- 《STM32F10xxx闪存编程参考手册》,《STM32 FLASH 模拟 EEPROM 使用和优化》
- 云途、s32k的参考手册,云途和stm32的sdk
- nor flash原理详细讲解
- NANDFlash原理
eeprom, norflash, nandflash特性
搬运自EEPROM, NAND FLASH, NOR FLASH
内部结构
EEPROM基于浮栅管单元(Floating gate transister)的结构。 EEPROM 的 单元是由FLOTOX(Floating- gate tuneling oxide transister)及一个附加的Transister 组成。由于FLOTOX 的特性及两管结构,所以可以单bit写。它的每个存储单元并联。
flash属于广义的EEPROM。FLASH 基于EEPROM, 与EEPROM主要的不同是FLASH 去除了 EEPROM 存储单元里的Tansister, 简化了存储电路(注意不是控制电路)。除此之外FLASH 的浮栅工艺不同, 所以写入速度更快。
NOR FLASH的每个存储单元(bit)以并联的方式连接到数据bit线,方便对每一位进行随机存取。同时具有专用的地址线(可以理解为字线),可以实现byte的直接寻址。NORFLASH具有足够的地址和数据线来映射整个存储区域,类似于SRAM的工作方式。例如,具有16位数据总线的2Gbit(256MB)NOR闪存将具有27条地址线,可以对任何byte进行随机读取访问。所以NORFLASH可以按byte读取。
NAND FLASH各存储单元(bit)之间是串联的。在读取数据时,当字线和位线锁定某个晶体管时,该晶体管的控制极不加偏置电压,其它的 7 个都加上偏置电压而导通,如果这个晶体管的浮栅中有电荷就会导通使位线为低电平,读出的数就是 0,反之就是 1。所以每次读取都是读取一行bytes里面的同一个bit, 最后整合为一个块:它是按块读取。
成本,容量
EEPROM存储电路并联, 每个bit的存储单元还要多加一个三极管, 最复杂所以单位成本也最高(注意不是控制电路)
因此它容量最低。EEPROM都是几十kbytes到几百kbytes,基本没有有超过512K。
NOR FLASH去除了EEPROM存储单元的三极管,每个存储单元并联, 去除了EEPROM存储单元的三极管, 集成度较小, 所以单位成本高。容量一般为1~16MB。
NAND FLASH, 去除了EEPROM存储单元的三极管, 各存储单元之间串联, 所以集成度大,单位成本最低。容量一般为8~512MB。
写入
EEPROM和FLASH在写入新数据之前,必须先将一个单元擦除(写 1)。 然后再在相应位写0。
NOR&NAND FLASH 去除了EEPROM存储单元的三极管。 所以只能整块的擦除。每次擦除只能擦除一行字节的一个bit。这是一个降低了单位成本的折衷办法,因为这容易导致损耗:减少了总擦除/写入次数。擦除块越小擦除越快。 然而擦除块越小芯片面积和存储器成本增加。 与NOR闪存相比NAND闪存可以更经济高效地支持更小的擦除块。目前,NAND闪存的典型块大小为8KB至32KB, NOR Flash为64KB至256KB。
除此之外在NOR闪存中,每个字节在擦除之前都需要写入“0”。这使得NOR闪存的擦除操作比NAND闪存慢得多。例如,NAND闪存S34ML04G2需要3。5ms才能擦除128KB块,而NOR闪存S70GL02GT则需要约520ms来擦除类似的128KB扇区。这相差近150倍。除此之外NOR的擦除块更大,这就更慢了。
EEPROM和FLASH的浮栅工艺不同, 所以NANDFLASH写入速度最快, EEPROM居中, NOR最慢。
读取数据粒度与速度
EEPROM可以单字节读取。EERPOM一般用于低端产品,读的速度不需要那么快,真要做的话,其实也是可以做的和FLASH 差不多。它的每个存储单元并联。 所以它的特点是可以随机访问和修改任何一个字节,可以往每个bit中写入0或者1。
NOR FLASH可以单字节读取。NORFLASH的每个存储单元(bit)以并联的方式连接到数据bit线,方便对每一位进行随机存取;同时具有专用的地址线(可以理解为字线),可以实现byte的直接寻址。NORFLASH具有足够的地址和数据线来映射整个存储区域,类似于SRAM的工作方式。例如,具有16位数据总线的2Gbit(256MB)NOR闪存将具有27条地址线,可以对任何byte进行随机读取访问。所以NORFLASH可以按byte读取, 随机读取(给一个地址读一个字节)时间很短。
NAND FLASH以页为单位读取。NAND FLASH各存储单元(bit)之间是串联的。在读取数据时,当字线和位线锁定某个晶体管时,该晶体管的控制极不加偏置电压,其它的 7 个都加上偏置电压而导通,如果这个晶体管的浮栅中有电荷就会导通使位线为低电平,读出的数就是 0,反之就是 1。所以每次读取都是读取一行bytes里面的同一个bit, 最后整合为一个页:它是按页读取。 随机读取时间很长。NAND 的全部存储单元分为若干个块,每个块又分为若干个页,每个页是 512byte: 每个页有 512 条位线,每条位线下有 8 个存储单元。
NAND FLASH每页存储的数据正好跟硬盘的一个块存储的数据相同,这是设计时为了方便与磁盘进行数据交换而特意安排的。在NAND闪存中,使用多路复用地址和数据总线访问存储器。典型的NAND闪存使用8位或16位多路复用地址/数据总线以及其他信号,如芯片使能,写使能,读使能,地址锁存使能,命令锁存使能和就绪/忙碌。 NAND Flash需要提供命令(读,写或擦除),然后是地址和数据。这些额外的操作也使NAND闪存的随机读取速度慢得多。
NAND闪存的顺序访问持续时间通常低于NOR闪存设备中的随机访问持续时间。利用NOR Flash的随机访问架构,需要在每个读取周期切换地址线,从而累积随机访问以进行顺序读取。随着要读取的数据块的大小增加,NOR闪存中的累积延迟变得大于NAND闪存。因此,NAND Flash顺序读取可以更快。但是由于NAND Flash的初始读取访问持续时间要长得多,两者的性能差异只有在传输大数据块(超过1 KB)时才明显。
可靠性
EEPROM存储电路复杂, 具有较高的可靠性, 最稳定可以保存100年。
NOR FLASH存储电路比复杂, 具有比较高的可靠性。
NAND FLASH存储电路简单, 可靠性比较低。
闪存会遭遇称为位翻转的现象,其中一些位可以被反转。这种现象在NAND存储电路简单中所以位翻转比NOR更常见。NAND器件中的坏块是随机分布的。以前也曾有过消除坏块的努力,但发现成品率太低,代价太高,根本不划算。NAND需要对介质进行初始化扫描以发现坏块,并将坏块标记为不可用。一般来说NAND的Block0是没有位翻转的。随着擦除和编程周期在NAND闪存的整个生命周期中持续,更多的存储器单元变坏。因此坏块处理(错误探测/错误更正(EDC/ECC)算法。)是NAND闪存的强制性功能。 这导致NAND的控制器电路复杂。这个问题对于用NAND存储多媒体信息时不是致命的。 但如果用本地存储设备来存储操作系统,配置文件或其他敏感信息时,必须使用EDC/ECC系统以确保可靠性。
另一方面, NOR闪存坏块少,在存储器的使用寿命期间具有非常低的坏块累积。因此,当涉及存储数据的可靠性时,NOR Flash优于NAND Flash。可靠性的另一个方面是数据保留,这方面,NOR Flash再次占据优势,例如,NOR Flash闪存S70GL02GT提供20年的数据保留,最高可达1K编程/擦除周期,NAND闪存S34ML04G2提供10年的典型数据保留。
擦除次数
EEPROM 每次只需要擦除一个字节所以不容易损耗,可以擦写100w次。
NAND闪存编程和擦除次数比NOR闪存好10倍。在NAND闪存中每个块的最大擦写次数是一百万次,NOR的擦写次数是十万次,NAND存储器除了块擦除次数优势, 典型的NAND块尺寸要比NOR器件小8倍, 每个NAND存储器块在给定的时间内的删除次数要少一些。编程和擦除的数量曾是一个需要考虑的重要特性。随着技术进步,这已不再适用,因为这两种存储器在这方面的性能已经很接近。例如,S70GL02GT NOR和S34ML04G2 NAND都支持100,000个编程 - 擦除次数。但是,由于NAND闪存中使用的块尺寸较小,因此每次操作都会擦除较小的区域, 与NOR Flash相比其整体寿命更长。
XIP(eXecute In Place)
eXecute In Place,即芯片内执行、就地执行,是指CPU直接从存储器中读取程序代码执行,而不用再读到内存中。应用程序可以直接在flash闪存内运行,不必再把代码读到系统RAM中。
flash内执行是指nor flash不需要初始化,可以直接在flash内执行代码。但往往只执行部分代码,比如初始化RAM。好处即是程序代码无需占用内存,减少内存的要求。
EEPROM&NORFLASH 可以像内存一样读任意地址(任意字节),可以XIP,当然这也要看接口是不是内存接口,如果不支持随机读取就一般不行,大部分NOR flash带有SRAM接口,有足够的地址引脚来寻址,可以很容易地存取其内部的每一个字节。可以非常直接地使用基于NOR的闪存,可以像其他存储器那样连接,并可以在上面直接运行代码。有的Norflash可以并行连接实现XIP,也可以串行通过SPI实现XIP。对于PC这需要相应的总线桥(内存控制器)芯片支持, Soc内部要集成相应桥芯片, 挂接到PCIE或者AMBA总线。 桥芯片的硬件逻辑会实现串并转换,总线仲裁,Cache结构,Burst等逻辑。
NANDFLASH 是按块读取,随机读取太慢所以不适合XIP当然这也要看接口是不是内存接口,如果不支持随机读取就一般不行,NAND使用复杂的I/O口来串行地存取数据。 一般是8个引脚用来传送控制,地址和数据信息 NANDFLASH只是不适合做XIP,但并不是不能做XIP,它坏块多,读取也太慢。比如EMMC启动就必须要把代码load到RAM里才能启动,你看到某些芯片支持EMMC启动,必定是有片内程序把EMMC的代码读到了RAM里。
驱动复杂程度
NAND更容易遇到位翻转, 驱动和控制电路要复杂的多。在使用NAND器件时,必须先写入驱动程序,才能继续执行其他操作。NAND在每一行上有CRC位标记,以及一些用于指示行是否为好的位。NAND处理芯片将管理CRC计算,允许在读取时纠正位错误,并管理坏行。
在USB驱动器中,这一切都由USB接口芯片处理。在SSD中,它由SATA(或其他接口模式)芯片处理,因此CRC错误和坏点映射对用户来说都是不可见的。这意味着在NAND器件上自始至终都必须进行虚拟映射。NAND内存的可靠运行还需要损耗均衡(就是把擦除平均到每个块上),损耗均衡也由USB或SSD控制器处理,因此用户也不可见。
用途
通常,NOR闪存是需要较低容量,快速随机读取访问和更高数据可靠性的应用的理想选择,例如代码执行。
NAND闪存则非常适用于需要更高内存容量和更快写入和擦除操作的数据存储等应用。
LINUX嵌入式系统多用一个小容量的nor flash存储引导代码,用一个大容量的nand flash存放文件系统和内核。