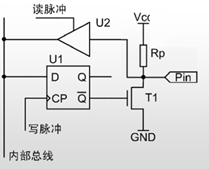
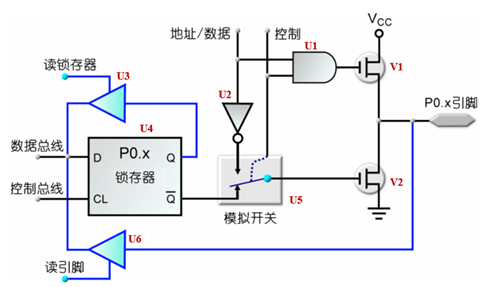
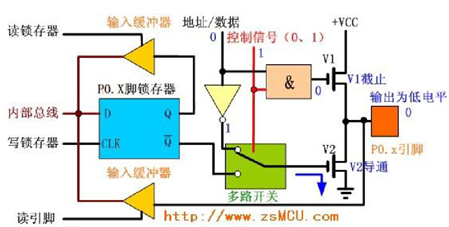
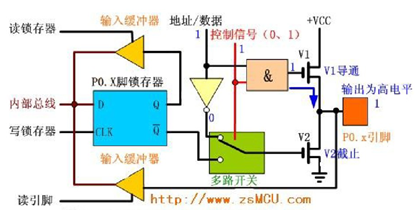
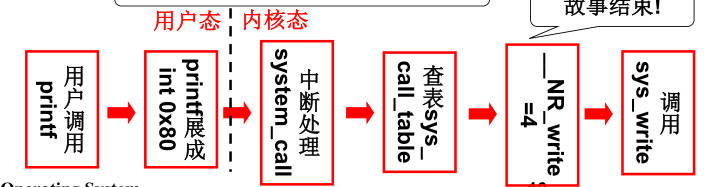
绪论 研究内容 本文介绍了如何设计一个以Altera FPGA为核心的网络摄像机,将图像传感器和MEMS麦克风作为的主要传感器,辅以千兆以太网模块、电源模块等模块,最终完成实现一个低成本易使用的网络摄像机的功能。要求该网络摄像机能够实时传输图像和音频信息,在电脑端可以将图像实时处理显示并将音频实时播放。此外,还能够将数据流存储在设备中,便于用户对视频进行回放等操作。
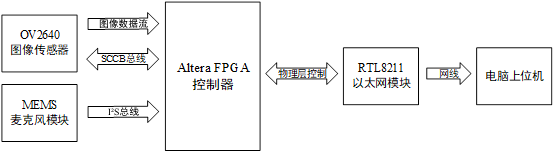
总体设计方案描述 本设计方案是以Altera FPGA为核心,在Quartus 18.0开发平台上,实现FPGA接收图像传感器和麦克风数据,并通过千兆以太网PHY芯片,将图像和声音数据发送至电脑上位机,电脑上位机利用Python3编程语言编写,在PyCharm IDE中执行,实现音视频实时播放和音视频回放的功能。主要由Altera FPGA控制器、图像传感器模块、麦克风模块、以太网模块和电脑上位机组成,系统框图如下图所示。
硬件选型 FPGA选用Cyclone IV EP4CE15 Starter Kit开发板。开发板板载W25Q64 SPI Flash芯片,8MB字节的存储容量,开发板给主控提供了50MHz的外部时钟源,芯片逻辑单元数为 15K LE,开发板引出了芯片的JTAG调试端口,引出了GMII千兆以太网接口,采用了RealTek的RTL8211EG芯片,引出了一个CMOS/CCD摄像头接口和40P的排座。开发板条件满足本设计的所有需求。
图像传感器选择经典的OV2640模组,OV2640适配开发板引出的40P的排座,提供了SCCB接口,可供配置传感器参数,可以配置最大1600*1200分辨率的图像输出,还可以配置JPEG压缩格式输出图像,模组拥有8位并口,可以高速输出图像信息,拥有帧场同步信号管脚,和电源使能管脚,方便FPGA控制和接收图像信息。
麦克风选择INMP441全向麦克风传感器,INMP441麦克风直接输出数字信号,采用的接口是I2S,非常适合FPGA去读取总线数据。传统驻极体麦克风输出模拟信号,选用INMP441省去了传统驻极体麦克所需的放大器、滤波器和模数转换器等硬件设计。
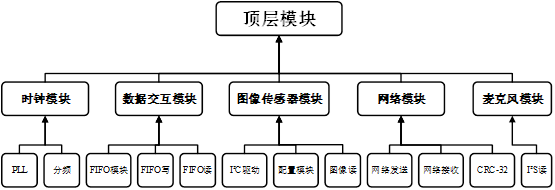
FPGA设计方案 FPGA设计采用模块化设计的方案,通过模块化设计,可以使一个大型设计分成多个模块,这样分工协作可使仿真测试更加容易,并且代码维护和代码升级也会更加方便。顶层模块不做逻辑设计,只通过例化调用子模块接口。因此,顶层模块下就由各功能模块组成,各功能模块下还可以分成多个子功能模块来实现。通过编译器对每个模块的综合仿真约束等设计,最后将所有模块连在一起,构成整个网络摄像机FPGA部分的设计。
本设计模块层次设计图如下所示,由时钟模块、数据交互模块、图像传感器模块、麦克风模块、千兆网络模块总共5个模块组成,各模块又由各个子模块组成,顶层模块通过例化的方式,将5个模块之间的接口互相连接起来,实现顶层模块的最终设计。该模块层次设计的各个子模块功能相对独立,各模块内部联系紧密,模块之间的连接简单,满足FPGA的模块化设计基本规则。
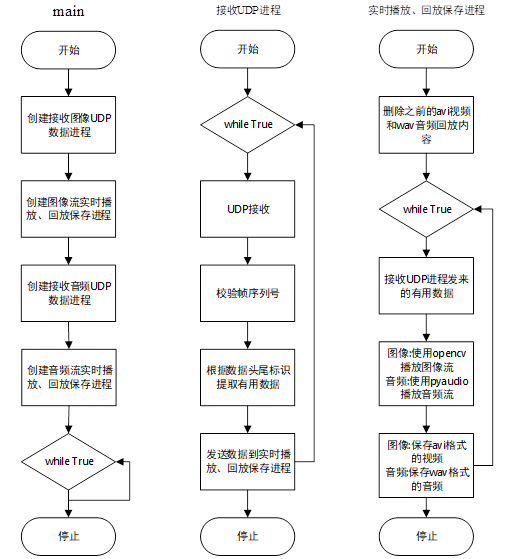
上位机设计方案 上位机采用Python3编程语言设计,主要功能分为接收数据包、实时解码播放、保存回放。FPGA传来的UDP数据包包含了音频和图像,两者通过两个不同的端口传输,这样更便于应用层的分开处理。在UDP数据包中还加入了帧序列号,上位机可通过校验前后两帧的序列号是否对应,来判断是否发生掉包的现象。实时解码播放是通过数据包的传输协议将有用数据部分取出,图像数据为JPEG压缩图像,通过OpenCV对JPEG图像解码,通过图像流的方式显示在屏幕上。音频是通过PCM码流传输,通过约定好的采样频率、量化位数、声道数等信息,调用PyAudio函数库接口进行播放。回放功能是将图片流保存成avi视频格式,音频流保存成wav音频格式,然后在电脑文件系统中可以打开进行回放。通过多进程多线程将这三个功能配合起来,通过流水线操作的方式,让整个上位机程序执行更加的高效、稳定。上位机的程序流程图如下图所示。
FPGA各模块功能实现 时钟模块实现 系统时钟输入和PLL配置 下图为FPGA开发板硬件原理图中的时钟部分,FPGA系统时钟信号由一颗50MHz有源晶振,从FPGA的T2引脚传入,由该时钟通过PLL锁相环和分频器,得到各模块所需的时钟,为整个系统提供准确的时钟信号。
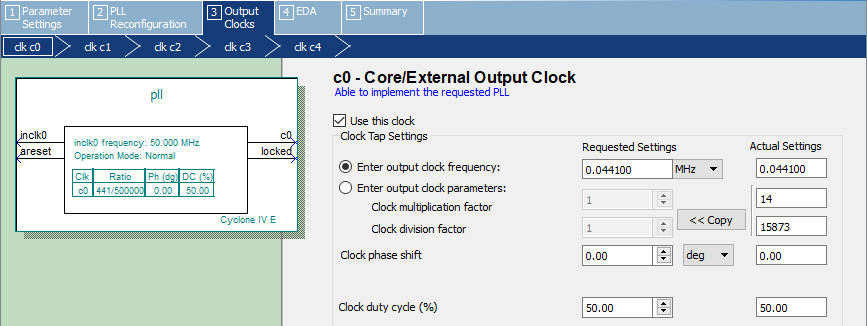
锁相环(Phase Locked Loop, PLL)是一种反馈型的控制电路,可以通过PLL对输入时钟进行系统级的时钟控制,可以配置管理时钟相位、偏移,具有倍频、分频和可编程占空比等功能。由于本设计使用到的模块较多,使用单一的时钟通过软件分频无法得到精准音频采样的频率,所以满足本设计要求。故使用PLL模块来满足该设计的不同时钟频率和不同时钟相位偏移的要求。通过Quartus提供的PLL IP核,对Altera FPGA片上的可编程PLL进行控制,使其输出各种时钟信号提供给各个模块使用。
下图为在Quartus 18.0中通过PLL IP核配置输入50Mhz时钟,输出2.205MHz时钟提供给麦克风模块的采样频率使用,配置软件会根据输入输出时钟频率自动计算出PLL的各个参数(时钟倍频参数、时钟分频参数),提供给麦克风模块的采样频率不需要相位偏移和特殊的占空比,故设置相位偏移为0,占空比为50%。
软件分频器实现 由于片上PLL资源数量有限,部分对时钟精准度要求不高的模块也可以采用软件分频器实现。例如I²C模块中的时钟信号采用250KHz,通过对输入的50MHz系统时钟上升沿或者下降沿计数,计数器值累加到100时,让输出信号产生翻转,即可产生250KHz的I²C驱动信号。这就是软件分频器的实现原理,占用硬件资源少,像这种整数倍分频,也可以提供较好的精度。
数据交互模块实现 设计FPGA各模块交互时,需要将图像和音频的数据传送给网络模块封装发送,故使用FIFO来做数据的缓冲。而网络模块的时钟信号是125MHz,与图像传感器模块24MHz和麦克风模块44100Hz有较大的区别,所以不能直接将数据通过同读写同时钟的FIFO传送给网络模块发送。FIFO模块可以配置读写相同时钟和读写不同时钟,在实际测试中,由于读取时钟为125MHz高频率信号,读写不同时钟情况下,FIFO的读写会产生严重的数据错误。因此本设计采用读写同时钟,FIFO模块输入时钟为网络模块的时钟125MHz,再手动编写跨时钟数据交互的时序逻辑,实现不同时钟域数据通过FIFO的转换。
FIFO模块配置 FIFO(First In First Out)模块是对数据缓冲时用到存储器,使模块可以被突发性读写。通常也被用于高速信号跨时钟域的数据交互,它可以被顺序写入,然后可以被顺序读出,先进先出的特性是FIFO不同于其他存储器的地方。
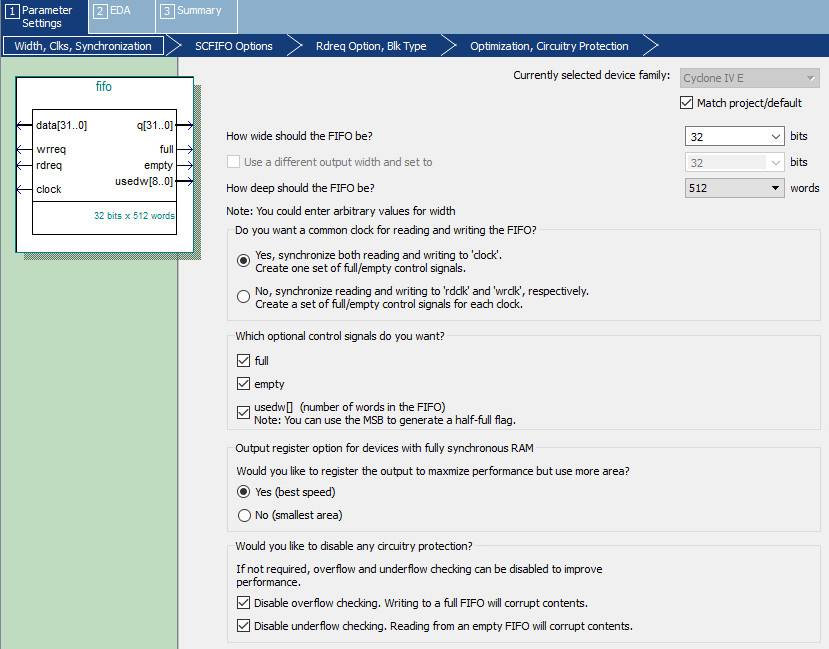
在Quartus 18.0中也可以通过IP核的方式来配置FIFO模块,关系FIFO容量的两个参数是FIFO的宽度和深度,宽度是指同时多少位可以被读写,深度是指可以存储多少该宽度的数据。由于FPGA中以太网是以字(4Bytes)的宽度来发送数据,并且以太网一帧默认最长大小是1500个字节,其中有用的数据为1472个字节,因此这里选择宽度为32bits,深度为512words可以满足缓冲一阵的以太网数据包。这里配置时我们采用读写相同时钟,从而使FIFO高速稳定的运行。需要打开usedw[]的功能,让网络模块读取已经使用的FIFO数量,当已经使用的数量大于等于1472字节时,可以开始发送一帧以太网数据。在输出寄存器一选项中,选择要求时间同步,Yes(best speed),由于FIFO时钟是125MHz,不选速度优先的话也会导致FIFO读写混乱错误。同时关闭上下溢出检测以提升FIFO模块性能。下图为最后FIFO模块配置的部分参数,配置时一定要使性能最优。
将数据写入FIFO模块实现 FIFO模块的时钟为125MHz,在图像FIFO存储模块中,图像传感器的时钟是24MHz,并且是8位宽度,需要手动编写跨时钟数据交互的时序逻辑,实现不同时钟域数据通过FIFO的转换。图像FIFO写模块输入有时钟、复位、图像数据、数据有效使能、垂直同步信号,输出有32位FIFO写入、FIFO写使能信号。捕获四个数据有效使能信号上升沿,将4个8位数据合并成1个32位数据,并向FIFO模块发送写使能,由于FIFO模块的时钟为125MHz,要写1个数据到FIFO模块,写使能信号高电平时间只能为8ns。为了使每幅图像不会等到下一张图像数据写入FIFO,直到FIFO满1472字节才发送,即使每幅图像都可以在该图像接收结束被发送完成,在垂直同步(一幅图像数据结束)信号产生后就向FIFO中追加写入1472个字节的0x00数据。
麦克风模块和网络模块也通过FIFO传递数据,麦克风模块的采样频率为44100Hz,也需要做个时钟转换和数据宽度转换,转换成FIFO模块的125MHz和32位宽才能写入FIFO,实现方法与图像数据写入FIFO模块类似。由于音频数据的采样量化位数是24位,转换成32位数据需要在首位补0x00,为了上位机方便保存成wav格式,采用小段存储方方式写入FIFO模块。
从FIFO模块读取数据实现 网络模块在判断FIFO存储数量大于等于1472字节时会开始发送数据,发送数据时会请求读取FIFO模块数据,以太网发送数据的时钟是125MHz的,读取FIFO数据后要及时锁存,在锁存进入稳态后才可以被网络模块读取发送,否则由于FIFO发送速度过快,数据在信号线上容易未进入稳态被读取,造成读取和发送的数据出现错误。因为音频传送的数据量小,且实时性要求高,所以音频FIFO模块读取的优先级要设置比图像FIFO模块读取的优先级高。
图像传感器模块实现 I²C驱动模块实现 使用OV2640传感器,需要用SCCB类I²C总线配置OV2640传感器的寄存器。I²C总线协议由飞利浦公司发明,由一根数据线和一根时钟线构成,属于半双工同步通信,较常用的时钟速率有低速模式100KHz,高速模式400KHz,超高速模式3.4MHz。I²C总线协议支持一主多从,由于I²C总线协议中设备标识符占7位空间,所以I²C总线理论可以挂载128个设备,但实际考虑I²C总线上设备的驱动能力,只可以挂载5个左右从设备。
I²C总线协议发送起始位后开始通信,起始位的标识是时钟线为高电平时,数据线从高电转变为低电平。通信时发送的第一个字节高7位内容为从设备的设备地址,末一位为读或写请求,低标识写标志位,反之则是读标志位。I²C通信协议中每发送一个字节后一位(第9位),对应的从机接收到就要发送应答响应,即第9位需要将数据线拉低响应,若主机读取到第9位仍为高电平,则标识无对应从机应答。发送设备地址后,若从机有应答,则主从双方继续通信,若主机写请求,就可以发送数据,向从机对应寄存器地址写入数据,从机收到数据后会返回应答信号,若主机读请求,则从机会向主机发送对应地址的数据内容,主机在接收后也需要拉低数据线响应。通信结束后主机发送停止位信号,停止位的标识是时钟线保持高电平,数据线从低电平转变为高电平的状态。
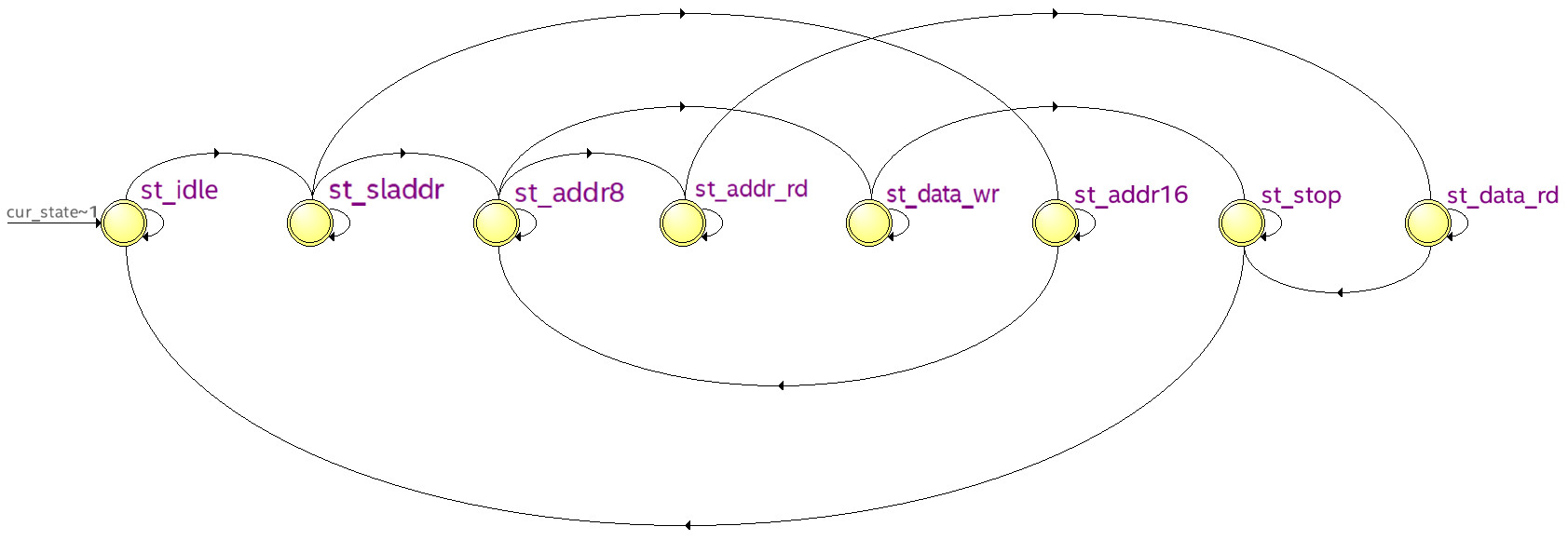
在FPGA中实现I²C驱动相对别的通信方式(USART、SPI等)难度较高,因为I²C驱动存在有多个工作状态,需要采用复杂的有限状态机来实现I²C驱动。下图是FPGA程序的有限状态机状态转移图,I²C驱动部分程序的代码见附录。
图像传感器配置模块实现 OV2640图像传感器有较多的寄存器,参考数据手册配置,在图像传感器配置模块中总共配置了201个寄存器,通过case语句,用查表的形式读取相应寄存器地址和寄存器数据,发送给I²C驱动模块,配置OV2640图像传感器。
先对传感器软复位,后根据本设计的需要配置寄存器,例如:分辨率采用UXGA模式,对输入时钟不分频,倍频系数2,配置JPEG输出,设置图像窗口大小和图像尺寸大小等。配置的程序代码和各寄存器的配置的值见附录。在配置完成后,图像传感器配置模块会发送给图像数据读取模块OV2640初始化完成信号。
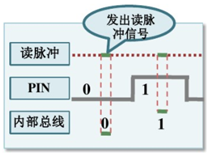
图像数据读取模块实现 图像传感器数据通讯接口采用的是DCMI接口,在OV2640中DCMI接口是8位数据并口,并且配有行同步垂直同步信号。行同步信号高电平时为图片中一行像素点有效数据,低电平为无效数据,所以每当出现行同步信号上升沿时就是该幅图像传输新的一行标识位。垂直同步信号是一张图片中有效数据的标识,当垂直同步高电平时为有效,每当出现垂直信号的下降沿时,表示该幅图像传输完成,当出现垂直信号的上升沿时,表示新的一幅图像传输开始。
图像数据读取模块收到配置模块发来的初始化完成信号后开始采集数据,在OV2640传感器实际应用中,图像传感器传来的前几幅图像会有显示问题,所以将开始传来的数据丢弃,根据垂直同步信号计数,第10幅图像开始开始采集图像数据发送给写FIFO模块。数据读取模块实现的代码见附录。
麦克风模块实现 I²S总线数据读取模块实现 使用的MEMS硅麦克风采用的是I²S通信协议,当INMP441的L/R引脚为低电平时,INMP441提供单个左通道音频数据,时序图如下图所示。和I²C比较而言,I²S多了个WS接口,WS接口是串行数据声道选择,为低时左声道麦克风模块在I²S总线上发送数据,右声道是高阻态。WS为高时右声道麦克风模块在I²S总线上发送数据,而左声道是高阻态。
根据时序图可以编写FPGA的I²S驱动,可见经过WS的一周期会得到一组声音信号,WS在SCK下降沿时跳变,在WS跳变后的第二个SCK上升沿可以读取音频数据的最高位,依次24个SCK后得到完整的24位左声道音频数据。设计FPGA程序时,一周期WS会有50次SCK上升沿,因此SCK的频率会比WS高50倍,要保证采样率为44100Hz,就需要通过PLL模块给麦克风模块提供2.205MHz的SCK信号。具体的I²S驱动代码见附录。
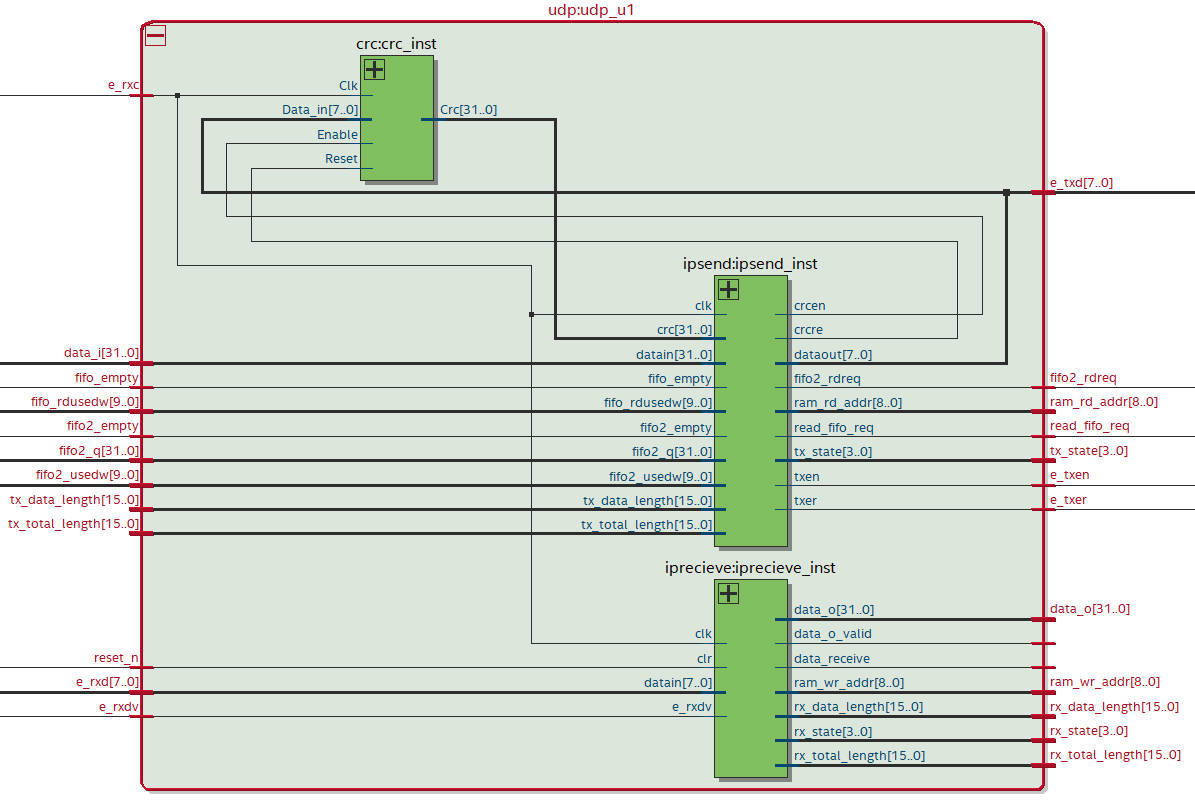
千兆以太网模块实现 千兆以太网模块是本设计FPGA部分实现起来最复杂和困难的模块,由于千兆以太网PHY芯片采用125MHz高速时钟和8位并口数据传输,容易导致数据传输时未进入稳定态,出现时序混乱的现象。网络模块由三个部分组成,分别是网络发送模块、网络接收模块、CRC-32校验模块,三个模块之间的连接关系RTL视图如下图所示。
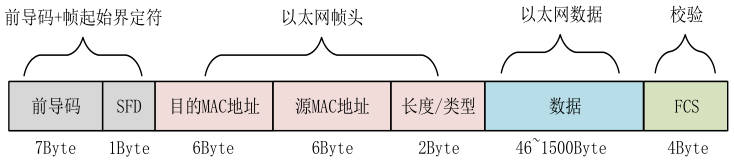
CRC-32校验模块实现 以太网帧组成如下图所示,它是由前导、帧起始定界符、以太网帧头、以太网数据、帧校验序列组成,其中网络中帧校验序列使用最广泛的是采用4字节的循环冗余校验方式,即CRC-32校验。
CRC-32计算方式可以采用串行或并行计算,为了发挥FPGA并行优势,本设计采用并行的方式计算CRC-32校验码,并行CRC-32计算的表可以由工具生成。在FPGA设计中,该模块输入的值有时钟、使能、一字节数据,以太网每发送一字节数据,就要将发送的数据值发送给CRC-32校验模块,会根据上次CRC-32的结果和本次传来的数据值,同步更新CRC-32的值,最后输出为CRC-32校验的结果加在以太网帧的帧尾发送出去,如果目的主机校验CRC-32结果失败,则会在数据链路层丢弃该帧。具体的CRC-32校验模块实现代码见附录。
千兆以太网数据发送模块实现 实现以太网数据发送模块,要解决两个问题,需要发送的数据包含哪些信息,需要如何控制千兆以太网PHY芯片。
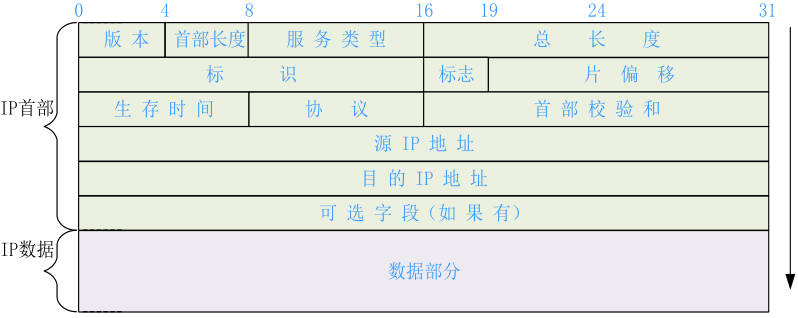
在CRC-32校验模块实现一节中介绍了以太网帧的组成结构,在发送目的MAC地址时使用ff-ff-ff-ff-ff-ff广播地址。以太网帧中的以太网数据段格式如下图所示,由于网络摄像机传输要满足实时性,且网络传输在局域网环境下环境不复杂,所以采用UDP协议传输数据,即在IP首部选择协议的地址中写入17表示UDP,生存时间一般为64,标识部分需要每次发送后累加,首部校验和是对IP首部内容累加保留末四位进行校验,在本设计中将源IP地址(FPGA的IP地址)设置为192.168.0.2,目的IP地址(电脑的IP地址)设置为192.168.0.3。以太网数据一般不超过1500字节,IP首部占了24字节,所以IP数据部分最大可为1476字节,其中IP数据的首四字节为用户自定义的帧序列号,用于上位机校验是否有丢包现象产生,所以实际每帧的IP数据中传输有用信息的只有1472个字节。
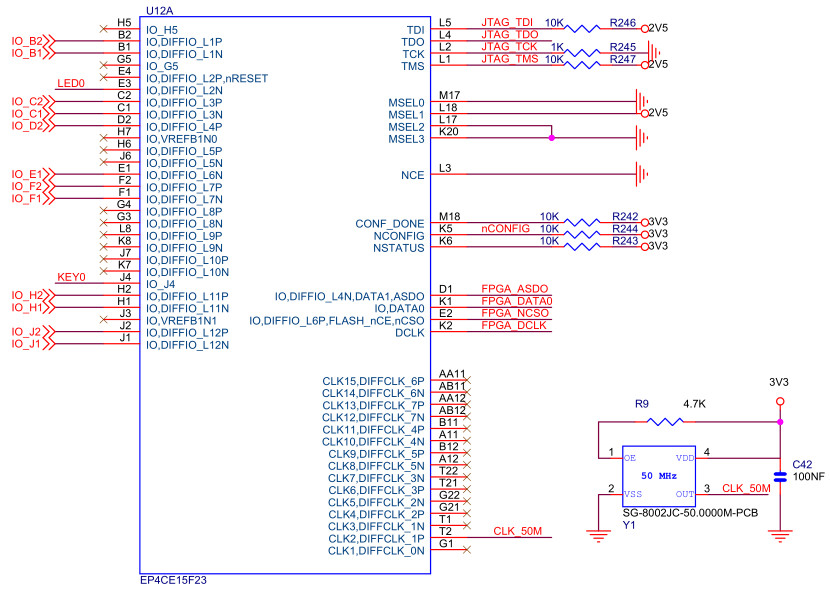
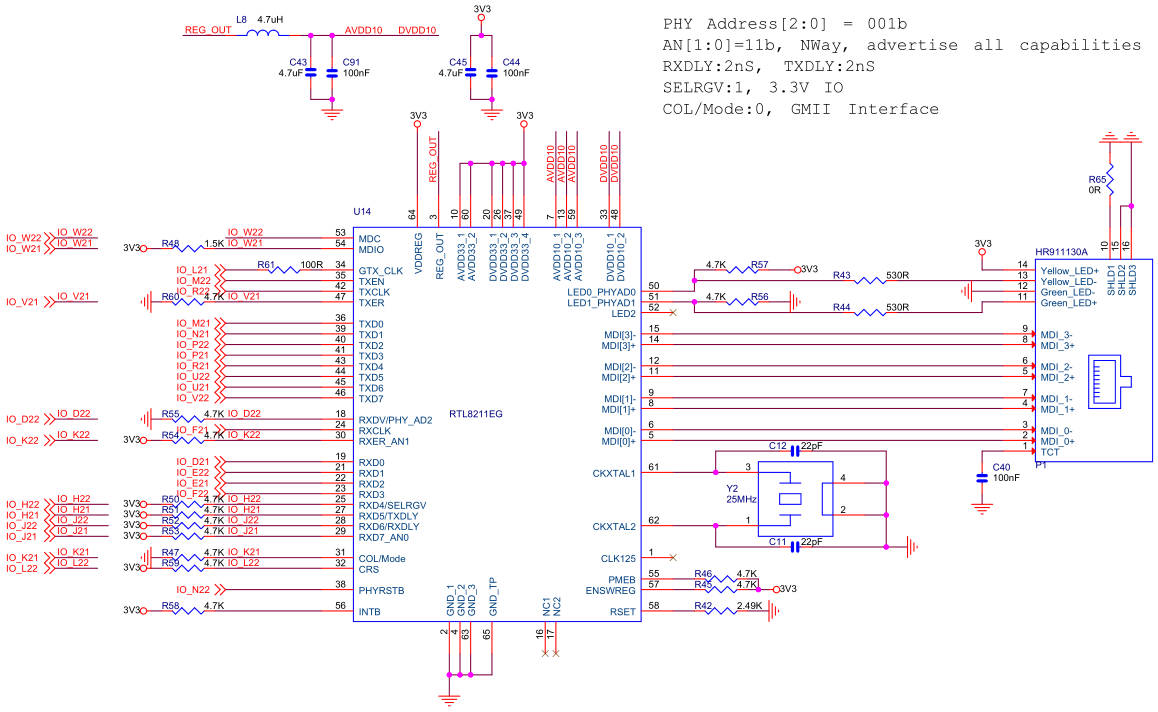
下图为物理层芯片RTL8211的硬件原理图,可见RTL8211与FPGA的连接主要包含8个发送引脚、8个接收引脚,还有发送和接收的时钟引脚,MDC和MDIO属于配置RTL8211芯片寄存器的接口,在本设计中采用默认寄存器值,所以未用到配置引脚。RTL8211发送和接收时钟均为125MHz,上升沿采样,发送和接收均为8位并口,可以满足1000Mbps全双工通信。
设计千兆以太网数据发送模块也是用有限状态机实现,使用了idle, start, make, send55, sendmac, sendheader, sendpicdata, sendmicdata, sendcrc共9个状态。在idle状态的时候,程序主要是初始化数据,并且检测图像FIFO和音频FIFO是否有超过1472个字节,其中先检测音频FIFO的使用量,若有超过1472个字节跳转到下个状态start。在start状态中会对IP首部进行配置,如果是图像FIFO大于1472字节,会配置端口号为8080,如果是音频FIFO大于1472字节,会配置端口号为8081,配置完成后会跳到下一个状态。make状态中会对IP首部计算校验和,并写入IP首部配置变量ip_header中,跳转至send55状态。在send55状态下,FPGA会和RTL8211通信,发送7字节前导码0x55和1字节帧起始界定符0xD5,发送完成后跳转到下个状态sendmac。在sendmac状态中会发送以太网帧头,包含目的MAC地址,源MAC地址,长度类型这些信息。下个状态sendheader,即发送start状态下存入ip_header变量中的IP首部信息,接下来进入发送数据的状态。发送数据的状态分两种一种是发送图像的状态,另一种是发送音频数据的状态,两个实现的方法一致,只是FIFO读请求所对应的FIFO不同,在发送数据状态中要先发送帧序列号,图像和音频的帧序列号是分开的,发送完帧序列号后循环请求读FIFO368次,将1472字节数据发送给RTL8211芯片,RTL8211会将从FPGA接收到的数据通过网线中的两对差分信号线发送到电脑网口。发送数据状态结束后进入最后一个sendcrc状态,该状态下会读取最后CRC-32的校验值发送给以太网PHY芯片,该状态结束后,表示一帧以太网数据传输结束,状态又跳转至空闲状态检测两个FIFO使用量。具体实现详见附录代码。
上位机功能实现 图像功能实现 接收和解析图像数据包功能实现 接收UDP的数据包使用了Python中socket库,在程序开始引用该库,通过socket.socket(socket.AF_INET, socket.SOCK_DGRAM)构造函数构造一个套接字,配置使用UDP协议,并且通过server.bind(‘192.168.0.3’, 8080)绑定该套接字对应的IP地址和端口号。接收UDP数据包通过函数server.recvfrom(BUFSIZE),其中BUFSIZE为缓冲大小,由于一帧以太网数据1472字节,这里将BUFSIZE设置为1472*1000,以实现每次接收缓冲区满足处理的速度。在每次接收UDP数据包后,首先会校验帧序列号,即数据区前四字节,帧序列号是否为上次接收的累加1,若帧序列号不连续则表示存在丢包的现象,通过打印verify error告诉用户帧序列号校验失败。处理图像数据时,传来的图像数据时JPEG编码格式,由于JPEG编码格式帧起始标识符值为0xFFD8、帧结束标识符值为0xFFD9,提取数据包中的有用数据就是通过find(0xff, index)函数找到0xff功能标识符,然后再判断的下一字节是否为0xD8,若判断为真即表示找到JPEG图像数据头,再找尾标识符0xFFD9,通过同样的方法找到数据尾标识符后,将JPEG图像数据包头到包尾数据通过fp.write(data)函数写入jpg格式的文件,就完成了一张图像的保存。
图像流实时播放功能实现 要实现图像流实时播放功能,需按照拍摄图像的帧率,连续读取保存在磁盘中的图像,再在屏幕上不断刷新显示。本设计上位机程序采用OpenCV函数库实现图像的读取,解码和显示的功能。首先,在程序的开头通过import cv2引用OpenCV库。通过img = cv2.imread(img_root + str(i)+’.jpg’, cv2.IMREAD_COLOR)读取jpg格式的文件,其中img_root为图像所在文件夹的名字,imread的第一个参数就是图像路径,将读取到的数据保存在mat对象img中。调用cv2.namedWindow(“video”, cv2.WINDOW_AUTOSIZE)创建一个显示图像的窗口,窗口名为video。最后通过cv2.imshow(“video”, img)函数,该函数可以让名为video的显示窗口中显示img图像信息。cv2.waitKey(55)函数是使该窗口显示时间为55ms,这个延时时间由视频的帧数决定。
图像流存储功能实现 OpenCV库中有支持导出avi视频的函数,fourcc = cv2.VideoWriter_fourcc(*’XVID’)函数,其中XVID参数是指将视频以MPEG-4编码类型保存,保存成avi格式的文件。videoWriter = cv2.VideoWriter(‘./avi/‘ + str(j) + ‘.avi’, fourcc, fps, size)函数配置了视频保存的路径,编码格式,帧率和每帧图像的分辨率,size = (1600, 1200)图像为1600 * 1200的分辨率。通过videoWriter.write(img)函数可以将img图像信息传入,让OpenCV处理生成视频。每隔150张图像发布一个10秒钟时长的avi视频,通过函数videoWriter.release()实现avi视频的发布。每次发布成功后程序会打印release告诉用户,可以在avi文件夹下查看保存的回放视频。
音频功能实现 接收和解析音频数据包功能实现 接收音频数据的方式与接收图像数据方式相同,通过Python的socket库。在接收音频数据后做帧序列号校验,并提取有效部分。接收到的音频数据是24位的麦克风adc原始值,由于自己电脑声卡输出只支持16位,播放24位音频会没有声音,故在上位机上做了个24位转换为16位的操作,即提取高16位数据,保存到pcm文件中。使用20ms的数据缓冲时间,分别将20ms的pcm数据保存到电脑中。
音频流实时播放功能实现 上位机使用pyaudio库播放PCM音频,在程序的开始通过import pyaudio引用该库,读取已经保存在硬盘中的音频数据,通过p = pyaudio.PyAudio()初始化音频播放器,由于PCM是音频的原始数据,不包含量化位数、通道数、采样率等参数,所以,通过stream = p.open(format=p.get_format_from_width(2), channels=1, rate=44563, output=True)配置要播放音频的参数,并赋值给stream对象。通过stream.write(data)向stream播放器对象中写入音频数据,就可以完成音频的实时播放。
音频流存储功能实现 使用wave库,将pcm音频保存成wav格式的音频文件写入磁盘,为了方便回放,每10s中保存一个wav音频。通过wavfile = wave.open(‘./wav/‘ + str(j) + ‘.wav’, ‘wb’)打开一个wav文件,通过设置函数给wavfile对象设置音频的通道数、量化位数和采样率。最后通过wavfile.writeframes(data)就可以往wav文件中追加音频内容,每10s保存成一个文件。
通过多进程实现各个功能 多进程并行工作实现 为了让程序高效运行,发挥CPU的多核优势,采用多进程并行的思想来实现上位机的设计。使用多进程可以实现流水线架构,例如,让解码显示图像的操作不阻塞接收UDP数据。在本上位机中共使用了四个进程,分别是图像接收数据和解析数据进程、音频接收数据和解析数据进程、图像实时显示和保存回放进程、音频实时播放和保存回放进程,四个进程互不影响,并行运行。在Python中使用multiprocessing库可实现多进程,例如创建接收和保存数据的进程p1 = multiprocessing.Process(target=receive_save_process, args=(pipe[0], )),第一个参数是传入进程所执行的函数,第二个参数是所要执行的函数对外的参数接口。通过p1.start()就可以使进程开始运行。
数据包进程间通信实现 在Python中进程间通信的常用方式有文件IO,共享内存,管道,消息队列等。通过文件的方式内存通信比较占用IO资源,为了使视频有更好的实时性,本设计采用管道和IO流的方式进程间通信。通过fp = io.BytesIO()创建IO流让fp指向该字节流,fp可以像文件一样通过write函数被写入,通过read函数读取IO流中的数据。多进程库提供了管道这种通信方式,通过multiprocessing.Pipe()创建管道。在多进程通信中,将数据写入IO流,并通过管道传输IO流的地址,使数据可以在内存中被交互,从而达到减小传输时延,使视频更具实时性。
系统性能测试与功能展示 系统性能测试 FIFO和以太网高带宽传输测试 FPGA编写测试模块,往FIFO模块中高速写入数据,再从FIFO中读取出进行对比,若对比不正确则亮红灯提示。测试的数据需要每次都不一致,竟可能有多个位产生变化,可以采用随机值。噪声的ADC值可以作为硬件真随机值,在本设计中通过麦克风传感器的低八位ADC值来作为测试数据,通过测试FIFO可以在125MHz频率下全速读写。
以太网测试也是采用比对发送和接收到的数据,由于发送和接收数据无法简单的通过其他的方式高速传输,所以要发送的数据选择有规律的数据。数据选择从0x00开始,下一字节都发送上一个数据加一后的补码,这样可以使每次发送的数据较上一次数据有更多的位会产生变化,通过此方法可以检测出更多的异常数据,若只通过单纯的数据累加测试,无法发现异常数据。经测试,以太网数据在200Mbps带宽下有较好的准确性,丢包现象不常发生,以太网在P2P模式下,全速传输千兆带宽数据时,丢包率为2%左右。
系统稳定性测试 对本设计经过长时间的稳定性测试,本设计不会产生图像卡顿,回放保存失败等现象,说明本设计具有良好的系统稳定性。
作品展示 下图为FPGA部分的图片,包含FPGA开发板、图像传感器和麦克风传感器。
总结与不足 毕业设计是对学生四年所学知识的一次考察,也是对我们四年学习成绩的一次考验。本次毕业设计让我学习了FPGA设计和上位机开发,经过此次毕业设计,我懂得了如何将一整个设计划分成多个小功能逐个实现,在联调的过程中也学习了如何分析问题和解决问题。通过本次毕业设计,让我懂得了学习其实是长期积累的过程,越往深的学会发现自己有越多的不会,所以在今后工作是也要学会敬畏知识,学习是个长期积累的过程,就算毕业工作会我也会持续学习,努力提高自己的综合水平。
本次毕业设计还有几个可以改进的地方:第一,在传输UDP的时候为采用丢包重传,上位机具备发现丢包的能力,可以在丢包发生时将帧序列号发回FPGA,请求FPGA重发数据。第二,上位机软件没有图形化界面,可以使用QT对上位机的图形化界面做开发。第三,FPGA可以尝试设计个MCU,在MCU中跑操作系统和lwip协议栈,使用TCP协议传输语音数据。本设计还有更多功能待完善。