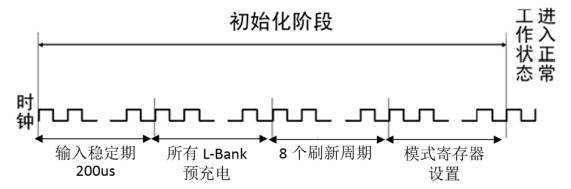
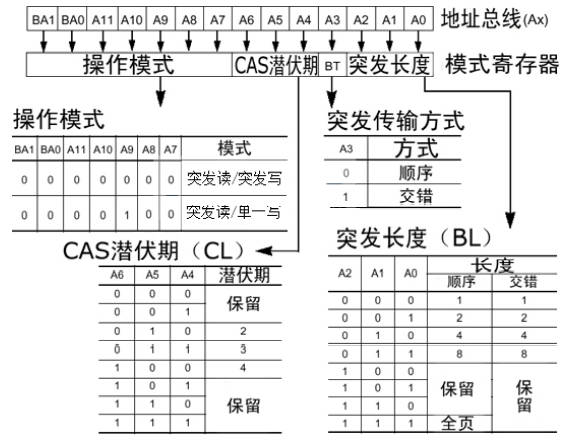
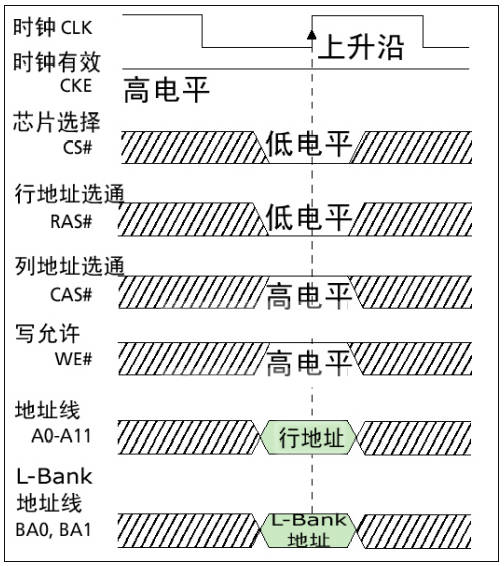
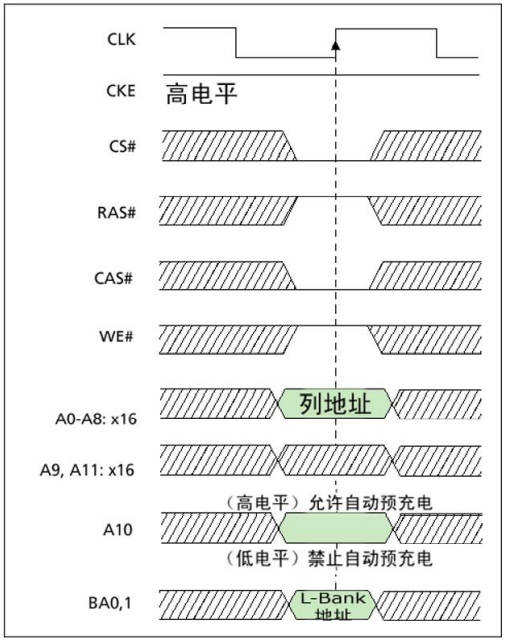
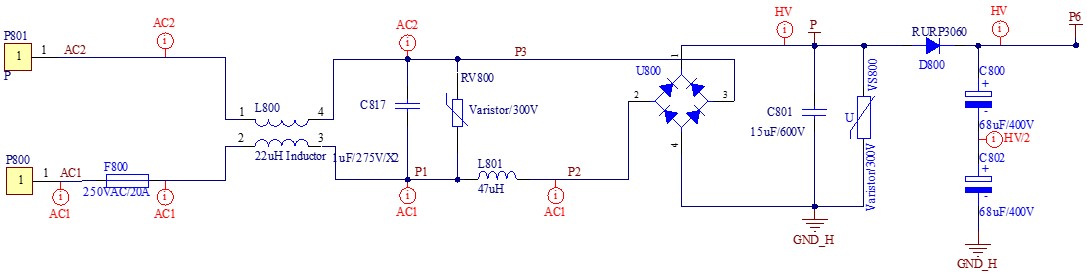
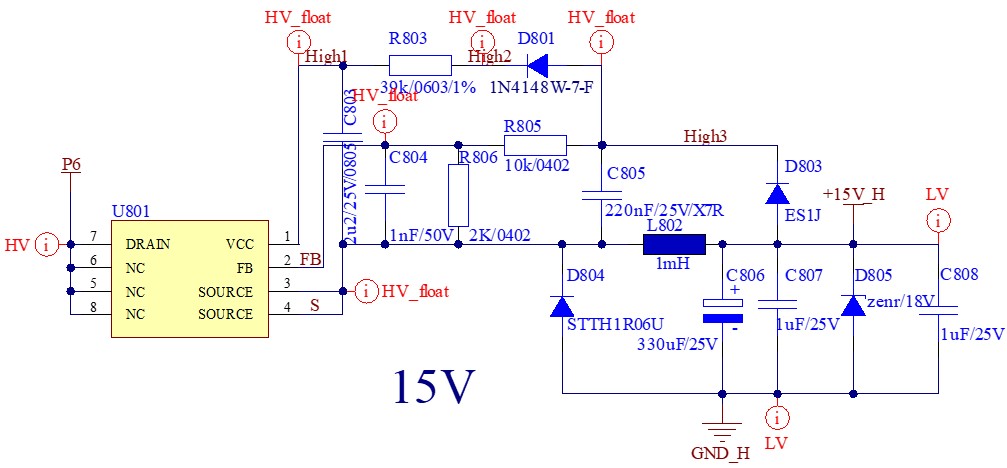
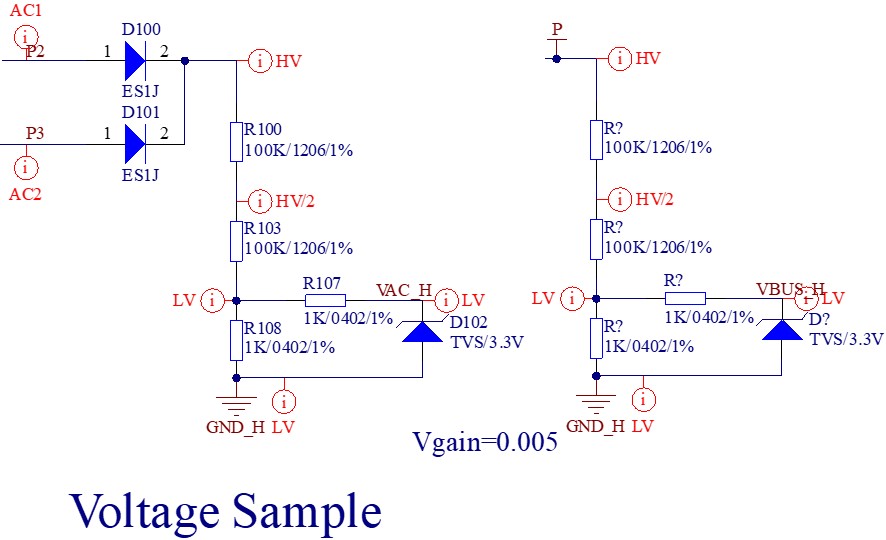
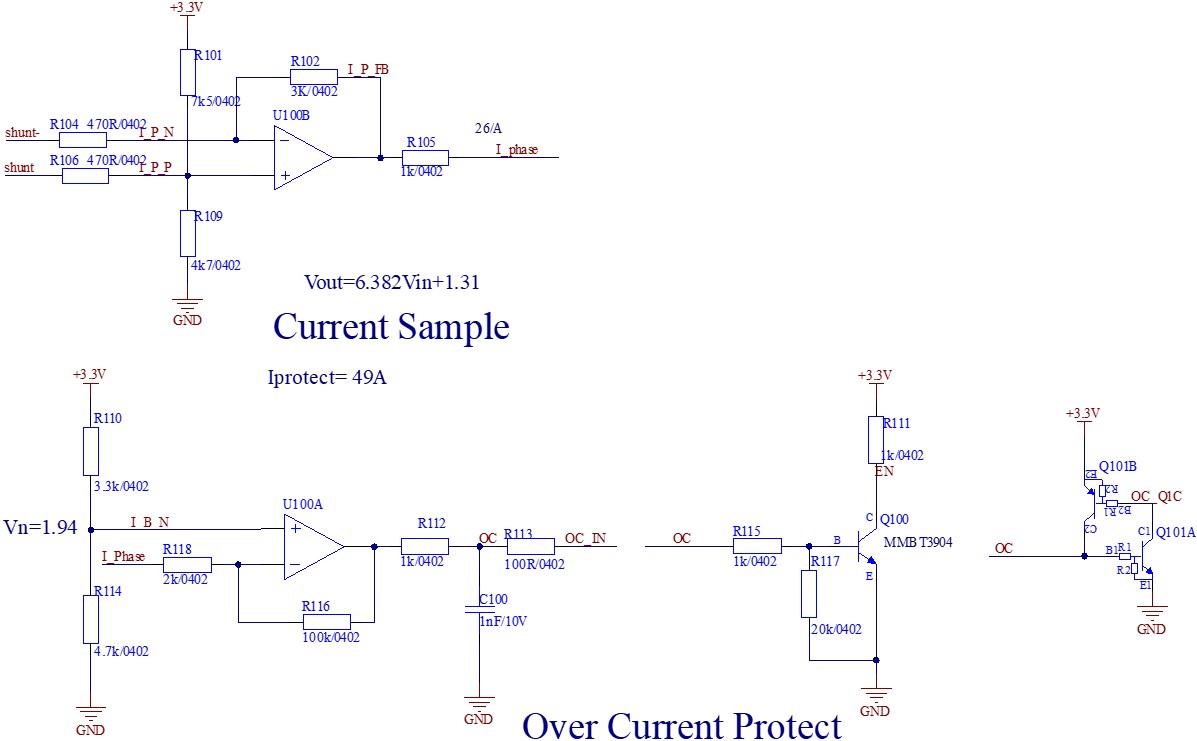
学习视频
以太网的介绍
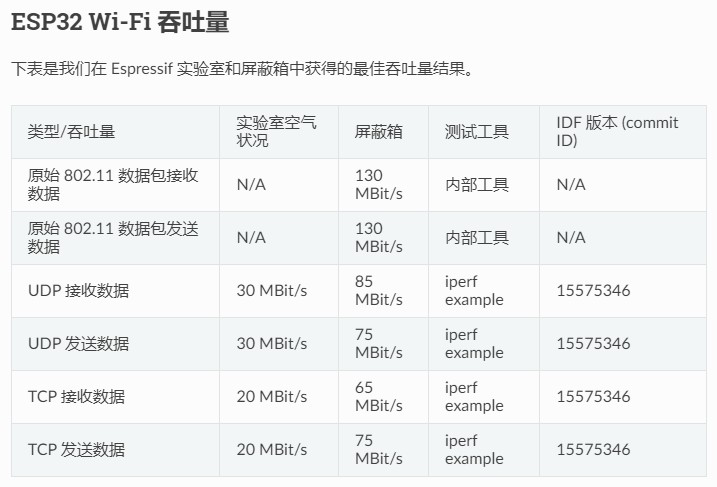
网络体系结构
- 物理层:在物理层上所传数据的单位是比特。发送方发送1(或0)时,接收方应当收到1(或0)而不是0 (或1),因此物理层要考虑用多大的电压代表”1”或”0”,以及接收方如何识别出发送方所发送的比特。物理层还要确定连接电缆的插头应当有多少根引脚以及各引脚应如何连接。当然,解释比特代表的意思,就不是物理层的任务。请注意,传递信息所利用的-些物理媒体,如双绞线、同轴电缆、光缆、无线信道等,并不在物理层协议之内而是在物理层协议的下面。
- 数据链路层:数据链路层常简称为链路层。我们知道,两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。在两个相邻结点之间传送数据时,数据链路层将网络层交下来的IP数据报组装成帧(framing),在两个相邻结点间的链路上传送帧(frame),每一帧包括数据和必要的控制信息(如同步信息、地址信息、差错控制等)。在接收数据时,控制信息使接收端能够知道一个帧从哪个比特开始和到哪个比特结·束。这样,数据链路层在收到一个帧后,就可从中提取出数据部分,上交给网络层。控制信息还使接收端能够检测到所收到的帧中有无差错。如发现有差错,数据链路层就简单地丢弃这个出了差错的帧,以免继续在网络中传送下去白白浪费网络资源。如果需要改正数据在数据链路层传输时出现的差错(这就是说,数据链路层不仅要检错,而且要纠错),那么就要采用可靠传输协议来纠正出现的差错。这种方法会使数据链路层的协议复杂些。
- 网络层、运输层、应用层见《计算机网络》书籍;fpga跑eth主要用到了phy层、数据链路mac层、网络层、udp传输层;
FPGA数据包内容
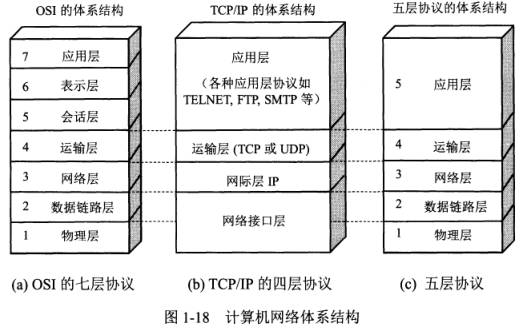
下面放出fpga发送的以太网数据包的组层图,图片来自《开拓者FPGA 开发指南V1.3》,相关介绍也可以查看PDF。
以太网数据包格式
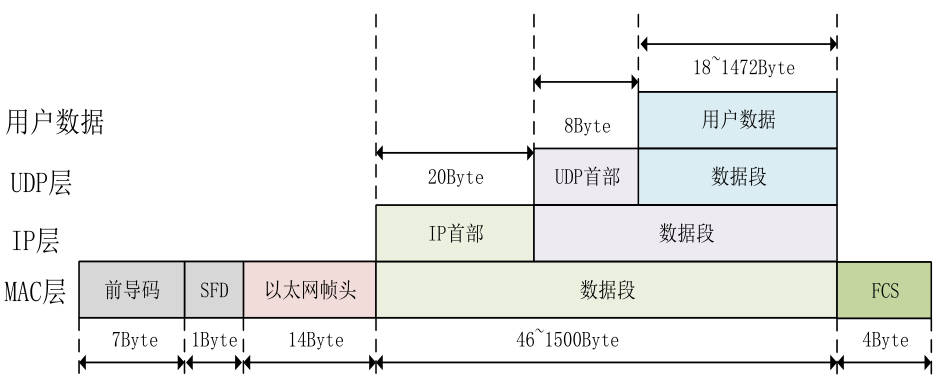
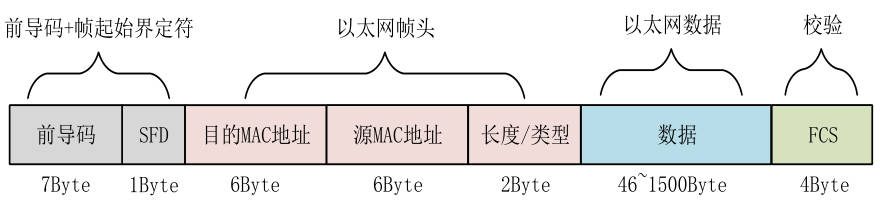
以太网帧格式
IP数据包格式
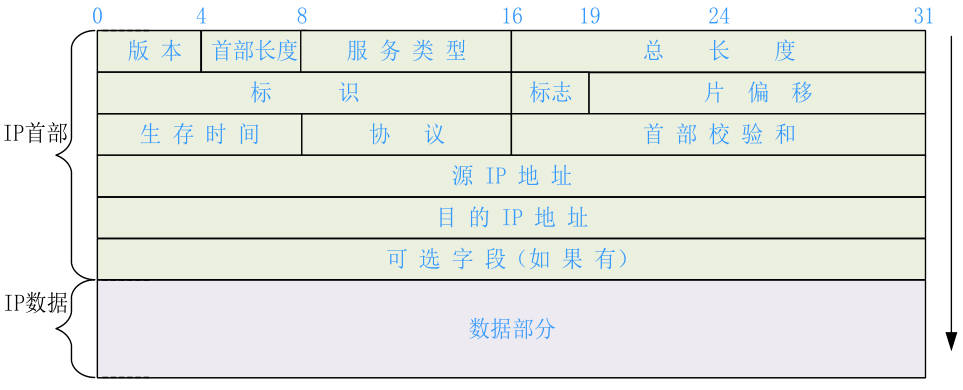
UDP数据格式
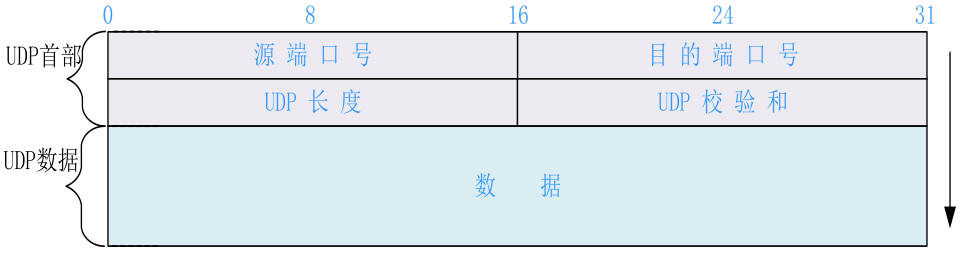
千兆以太网物理层
- 下面这个是我开发板图和板上的千兆以太网原理图,设计的非常好,板子上的IO基本上都是等长线。

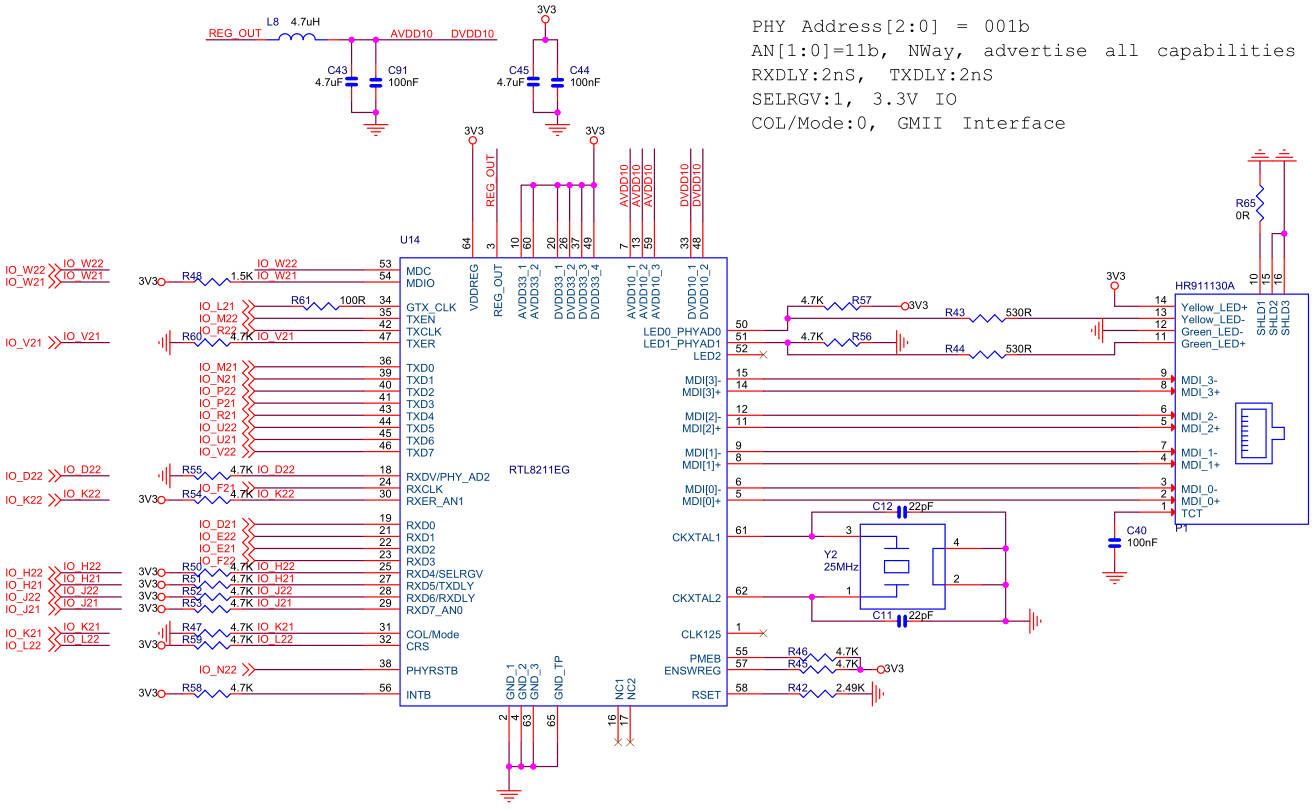
- 物理层的设计和学习还有个非常重要的学习资料就是《RTL8211数据手册》,这个手册上竟然写着不对外公布。
调试过程
例程修改
- 简易的修改了下例程,让udp每次数据包发送1472个字节数据,其中前4字节是包序列号,用于接收端检测是否掉包,其他的1468个字节数据为0x00-0xFF循环,从而更为精确的模仿正常传输时的内容。再通过每次发完控制idle时间来控制传输速率。
上位机编写
- 上位机才用Python编写,在JupyterNotebook里实现。实现原理主要就是一直读udp,再去比较这次的包序列号是不是上一次+1,如果不是的话打印出来。
1 | import socket |
掉包处理
- 在100Mbps速率传输的时候,每65536帧传输后都会出现2帧的掉包,通过WireShark查看,能找到那2帧包,也就是说数据包被网卡接收但是在上位机处没有接收。通过WireShark查看整个以太网数据包内容后发现规律:只有在IP数据包的首部校验和为0xFFFF的时候才会出现掉包,百度上也有这样的案例,于是修改FPGA代码,让IP包首部标识位不每次+1,这样校验和就不会出现0XFFFF。
调试结果
- 经过简易测试,当传输速率为200Mbps的时候,不掉包;当传输速率为300Mbps的时候,出现掉包。
总结
- 本次调试,学习了网络5层模型的物理层和MAC层,通过亲自实践解决出现的问题,对网络的底层实现有了更清楚的认识,对日后学习Linux驱动开发的网络部分会有极大的帮助,以及我的毕设,udp传输图像只是其中的一小部分,如果有时间,我会做个更复杂题目,学习更多的网络知识(大学只学了物联网和网络相关,计网没学)。